

Veri Bilimi / 22 Ekim 2023 / Miraç ÖZTÜRK
Merhabalar.
Bugün; yer aldığımız dijital çağda rekabet ve üstünlük adına firmaların veri elde etme çalışmalarında önemli bir role sahip olan Web Scraping (Web *Bilgi* Kazıma) üzerine bilgi ve notlarımı aktarmaya çalışacağım.
Şimdiden iyi okumalar.
Ama öncesinde;
Makalede Neler Var ?
Web Scraping Nedir?
Web Scraping; bir web sitesinden bilgi toplamak için otomatik yöntemlerin kullanılması tekniğidir.
Genellikle bu, web sayfalarını otomatik olarak indirip içeriklerini analiz eden programlar aracılığıyla yapılır.
Bu programlar farklı kaynaklarda Crawler (Web Crawler – Web Tarayıcsı) ya da Spider (Örümcek) olarak ifadelendirilmektedir.
Peki ama bu teknik neden kullanılmaktadır?
- Fayda Odaklı Çalışmalar: Bilim insanları, araştırmacılar ve analistler vb. akademik odaklı kişilerin araştırma amaçlı olarak kullanması. (Etik faliyetler adına.)
- Kâr Odaklı Çalışmalar: Kurum ve kuruluşların rekabet üstünlüğü sağlama ya da doğrudan gelir odaklı çalışmalar amaçlı olarak kullanması.
Bunlara birkaç örnek;
Fiyat Karşılaştırması: E-ticaret sitelerinden ürün fiyatları toplanarak, fiyat karşılaştırmasında bulunulması.
Pazar Araştırması: Rakip firmaların web sitelerinden veri toplayarak pazar trendleri hakkında bilgi sahibi olunması.
vb.
- İstekler Oluşturulması (HTTP): İlk adım; bir web sitesine erişmek için HTTP istekleri göndermektir.
Bu işlemler için; Requests gibi Python kütüphaneleri kullanılabilir. - Kaynak Analizi (Sayfa İçeriği): Sayfa içeriği analiz edilip; indirildikten sonra, veriyi ayıklamak için HTML ve CSS gibi metin dilleri kullanılır.
Bu işlemler için; Beautiful Soup veya Scrapy gibi Python kütüphaneleri kullanılabilir. - Veri Depolama: Ayıklanan veri; bir veritabanında (Kaynak) ya da fiziksel bir dosyasında (CSV vb.) saklanabilir.
Web Scraping Korunma Yöntemleri
Robots.txt Kullanımı
robots.txt dosyası; bir web sitesinin kök dizininde yer alan ve web tarayıcılarının (SEC – Search Engine Crawlers / Bots) bu siteyi nasıl tarayacağını belirleyen bir standart dosyadır.Bu dosya, hangi botların hangi kısımlara erişip erişemeyeceğini belirtmektedir.
Peki neden izin verilir?
Örneğin; GoogleBot. Google’un sitenizi taraması için gelişirtiği bot sistemi.
- URL listesi oluşturma,
- Sayfaları tarama,
- Yeni linkleri keşfetme,
- Sayfa içeriğini analiz etme
vb. görevleri vardır.
robots.txt ile çeşitli modellerde geçiş/engelleme işlemlerinde bulunabilirsiniz.
Bunlara yaklaşımlara yönelik birkaç örnek verecek olursak;
#Tum botlarin, tum sayfalara erisim engellemesi.
User-agent: *
Disallow: / #Tum botlarin, belirli bir sayfaya erisim engellemesi.
User-agent: *
Disallow: /ozel-sayfa.html #Tum botlarin, belirli bir klasore erisim engellemesi.
User-agent: *
Disallow: /ozel-klasor/ #Belirli botlarin (Googlebot), belirli bir klasore erisim engellemesi.
User-agent: Googlebot
Disallow: /ozel-klasor/ Rate Limiting Tekniği Kullanımı
Rate Limiting (İstek Sınırlama); bir kullanıcının (Genellikle bir IP adresi veya kullanıcı hesabı bazında) belirli bir zaman diliminde yapabileceği maksimum istek sayısını sınırlama tekniği/pratiğidir.
Bu yaklaşım; sunucunun kötü niyetli saldırılardan korunmasına, kaynakların adil bir şekilde dağıtılmasına ve sistem üzerindeki yükün dengelenmesine yardımcı olmaktadır.
Peki uygulama yöntemleri nasıl gerçekleştirilebilir;
- IP Bazlı Sınırlama: Kullanıcıların IP adreslerine göre istek sınırlaması yapma.
- Token (Anahtar) Bazlı Sınırlama: API anahtarları veya oturum tokenleri üzerinden istek sınırlaması yapma.
- Pencereleme Yöntemi: Belirli bir zaman diliminde (Örneğin; bir saatte bir.) izin verilen maksimum istek sayısını belirleme.
Fikir vermesi adına kısa bir örnek verecek olursak;
Bir API servisi; bir IP adresinin her 10 saniyede en fazla 5 istekte bulunmasına izin verebilir.
Eğer bu sınır aşılırsa; sunucu genellikle 429 Too Many Requests hatası döndürür.
Temsili mimari örnek;
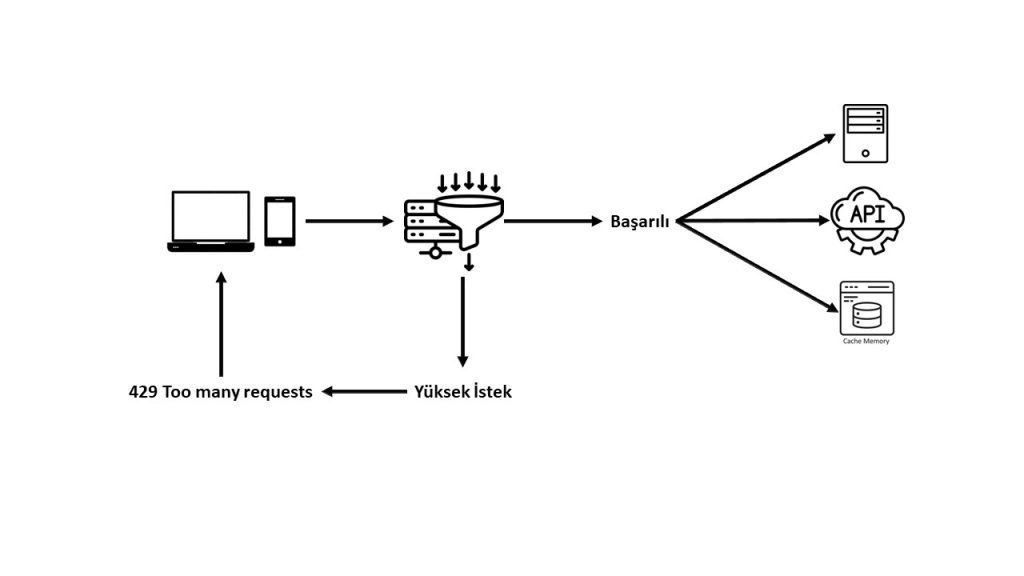
şeklinde ifade edilebilir.
Rate Limiting uygularken bazı dikkat edilmesi gereken noktalar mevcut.
Bunlar;
- İyi Tasarlanmış Geri Bildirim: Kullanıcılara ne kadar kaldıklarını ve ne zaman tekrar istekte bulunabileceklerini belirten, açık ve anlaşılır hata mesajları bildirilebilir.
- Beyaz Liste: Güvenli IP adresleri veya servisler, beyaz listeye alınarak bu sınırlamaların dışında tutulabilir.
- Dinamik Sınırlama: Bazı durumlarda, sistemdeki yükü göz önünde bulundurarak dinamik bir şekilde rate limiting uygulamak faydalı olabilir.
Rate Limiting; yüksek trafiğe sahip web siteleri ve API’ler için kritik bir güvenlik ve kaynak yönetimi stratejisidir.
Uygulama sahipleri; kullanıcı deneyimini olumsuz etkilememek için bu sınırlamaları dikkatlice planlamalıdır.
CAPTCHA Test Sistemi Kullanımı
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart); bilgisayarların ve insanların birbirinden otomatik olarak ayrılmasını sağlamak amacıyla tasarlanmış bir test sistemidir. CAPTCHA’nın temel amacı, otomatik botların ve scriptlerin belirli web işlemlerini gerçekleştirmesini engellemektir.
Bunların yanı sıra spesifik olarak ifade edecek olursak;
- Spam Engelleme: Formlara otomatik spam gönderimini engellemek için sıkça kullanılır.
- Web Scraping Önleme: Otomatik veri çekme işlemlerini engellemek için kullanılabilir.
- Brute Force Saldırılarını Önleme: Hesap giriş denemelerini sınırlamak için kullanılır.
- Kaynak Kullanımını Kontrol Etme: Sunuculara aşırı yük bindirebilecek otomatik işlemleri engellemek için kullanılır.
Bilinen ve geliştirilmiş olan CAPTCHA türleri;
- Geleneksel CAPTCHA: Kullanıcının bulanık veya şekillerle çarpıtılmış metni doğru bir şekilde girmesini talep eden görsel test türüdür.
- ReCAPTCHA: Google’ın geliştirdiği bir CAPTCHA türüdür.Genellikle kullanıcının resimler arasından belirli nesneleri seçmesini veya bulanık metni doğru bir şekilde girmesini talep etmektedir.
- Hareket Bazlı CAPTCHA: Kullanıcının belirli bir şekli belirli bir alana sürüklemesi gibi basit interaktif görevler veren test türüdür.
- Matematiksel CAPTCHA: Basit matematiksel işlem sonuçlarını girmeyi talep eden test türüdür.
- Sesli CAPTCHA: Görme engelli kullanıcılar için sesli komutlarla çalışan CAPTCHA test türüdür.
Görsel örnekler ile ifade edecek olursak;





şeklinde karşınıza çıkabilirler.
Peki bu kadar avantaj sağlıyorken, neden heryerde karşımıza çıkmıyor bu sistem?
Dezavantajları var mı?
- Kullanıcı deneyiminizi doğrudan etkileyebilir. (Etkilemektedir, yer yer tam ölçümlenemiyor.)
Zor ve okunması güç CAPTCHA’lar kullanıcılar için sinir bozucu sonuçlar oluşturabilir. - Tam koruma sağlamaz.
Gelişmiş OCR (Optical Character Recognition) yazılımları ve botlar, bazı CAPTCHA türlerini kolaylıkla aşmaktadır.Bu konuda firmalar spesifik olarak kendi test türlerini geliştirmektedir. - Erişilebilirlik sorunları oluşturabilir.
Bazı CAPTCHA türleri, görme veya işitme engelli kullanıcılar için zorlayıcı olabilir.
Honey Pot Tekniği Kullanımı
Honey Pot; siber güvenlik ve web güvenliğinde, kötü niyetli veya istenmeyen trafikleri yakalamak ve analiz etmek için kasıtlı olarak yerleştirilmiş sahte veya çekici görünen tuzaklardır.
*Honey Pot; kelime anlamıyla bal kavanozu demektir
Web sitelerinde honey pot tekniği, genellikle otomatik botların ve spamcıların aktivitelerini tespit etmek ve engellemek amacıyla kullanılır.
Honey Pot’un çalışma prensibi ise;
- Görünmez Form Alanları: Bir web formuna, gerçek kullanıcıların göremeyeceği (CSS ile gizlenmiş veya görünmez kılınmış) ama otomatik botların doldurabileceği sahte form alanları eklenir.
Eğer bu alan doldurulmuşsa, bu formun bir bot tarafından gönderildiği anlaşılır. - Sahte Linkler (Yönlendirme Linkleri/Bağlantıları): Web sayfasına, gerçek kullanıcıların göremeyeceği veya tıklamayacağı sahte linkler eklenir.Bu linklere tıklanırsa; bu trafiğin otomatik bir bot tarafından geldiği anlaşılır.
Temsili mimari örnek;

şeklinde ifade edilebilir.
Bu tekniğin kullanımdaki avantajları;
- Pasif Güvenlik: Honey Pot; kullanıcı deneyimini etkilemez veya ve kullanıcılarınıza rahatsızlık vermez.
Sadece botları tespit etmek için pasif bir şekilde çalışır. (Farkedilmez bir şekilde. vb.) - Düşük Yanlış Pozitif Oranı (Low False Positive Rate): Eğer doğru bir şekilde uygulanırsa, gerçek kullanıcıların tuzaklara düşme olasılığı düşüktür. (Kurgu planı belirleyici.)
şeklindedir.
Yanı sıra, oluşabilecek dezavantajlar ise;
- Gelişmiş Botlar: Bazı gelişmiş botlar, honey pot tuzaklarını tespit edebilir ve bu tuzakları atlayabilir.
- Yanlış Negatifler: Tüm otomatik trafik; kötü niyetli veya istenmeyen bir etkinliğin fark edilmeden geçtiği durumlarda da olabilir. (Yanlış kurgulama senaryosu.)
Dikkat edilmesi gereken noktalar/nüanslar ise;
- Gizlilik: Honey pot tuzaklarının gerçek kullanıcılar tarafından fark edilmemesi önemlidir.
Bu da etkili bir şekilde CSS veya JavaScript kullanılarak sağlanabilir. - Loglama: Tuzaklara düşen trafiği loglamak, kötü niyetli botların veya IP adreslerinin tespit edilmesine ve analiz edilmesine yardımcı olabilir.Ayrıca kurgunuzun doğruluğunu da test edebilirsiniz.
Honey Pot tekniği; web sitelerini otomatik botlardan koruma konusunda etkili bir stratejik çözümdür.
Ancak; bu tekniğin tam koruma sağlamadığı ve diğer güvenlik önlemleriyle birlikte kullanılması gerektiği durumların olduğu da unutulmamalıdır. (Etki sağladığı.)
Browser Fingerprinting Tekniği Kullanımı
Browser Fingerprinting (Tarayıcı Parmağı); bir kullanıcının web tarayıcısının ve cihazının özelliklerini toplayarak bu kullanıcının benzersiz bir profilini (parmak izini) oluşturma yöntemidir.Bu profil; kullanıcıları tanımlamak ve takip etmek için kullanılabilir, çoğu zaman çerezlerin (cookies) bir alternatifi veya tamamlayıcısı olarakta kullanılmaktadır.
Temsili mimari örnek;

şeklinde ifade edilebilir.
Browser Fingerprinting tekniği ile toplanan bilgiler arasında;
- Tarayıcı Versiyonu ve Tipi: Örneğin, Chrome 92, Firefox 88 vb.
- İşletim Sistemi: Örneğin, Windows 10, macOS Catalina, Linux vb.
- Ekran Çözünürlüğü: Kullanıcının ekranının piksel boyutları.
- Desteklenen Diller: Tarayıcıda seçili olan diller.
- Yüklü Eklentiler: Tarayıcıya yüklenmiş eklentiler ve versiyonları.
- Fontlar: Cihazda yüklü olan fontlar.
- Donanım Bilgisi: Özellikle WebGL ve canvas aracılığıyla GPU bilgileri.
- Zaman Dilimi: Kullanıcının bulunduğu zaman dilimi.
- Ek Çeşitli Ayarlar: Tarayıcının JavaScript özellikleri, cookie tercihleri vb.

şeklindedir.
Bu teknik ile elde edilen avantajlar;
- Dayanıklılık: Kullanıcılar çerezleri silebilir veya engelleyebilir, ancak fingerprinting bilgilerini değiştirmek daha zordur.
- Çerezsiz Takip: Çerezleri devre dışı bırakan kullanıcılarda bile takip sağlar.
Yanı sıra dezavantajları ise;
- Gizlilik Sorunları: Kullanıcıların izni olmadan gerçekleştirilen takip, gizlilik ihlallerine yol açabilir.
*KVKK – GDPR - Tam Olarak Benzersiz Olmaması: İki kullanıcının fingerprinting bilgileri bazen benzer olabilir, bu da analiz ve kullanıcı deneyimi kararları noktasında yanıltıcı sonuçlara neden olabilir.
Buna yönelik alınabilecek önlemler ise;
- Özel Göz Atma Modu: Tarayıcının özel göz atma modu, fingerprinting’i zorlaştırabilir.
*Birçok tarayıcı artık bu verileri tutmaktadır. EK HABER SAYFASI için lütfen tıklayınız. - Tarayıcı Eklentileri: Fingerprinting engelleyici eklentiler, bu tür takipleri sınırlayabilir.
- JavaScript Engelleyicileri: JavaScript’i engelleyen eklentiler, fingerprinting işlemlerinin birçoğunu engelleyebilir.
Browser Fingerprinting; kullanıcıları tanımlama ve takip etme yöntemlerinden biridir ve hem pazarlamacılar hem de gizlilik savunucuları için önemli bir konudur.Kullanıcılar ve web site sahipleri; bu teknolojinin getirdiği avantajları ve potansiyel gizlilik risklerini dikkate almalıdır.
IP Yönetimi (White List - Black List)
IP Engelleme; belirli IP adreslerinin veya IP adresi aralıklarının bir sunucuya veya web sitesine erişimini engelleme eylemidir.Siyah liste ise genellikle engellenmesi gereken bu IP adreslerinin, domainlerin veya diğer kaynakların listesidir.
Peki ne gibi faydalar sağlar;
- Güvenlik: Kötü niyetli faaliyetlerde bulunan IP adreslerini engellemek için.
- Spam Engelleme: Sürekli spam içerik gönderen IP adreslerini engellemek için.
- DoS – DDoS Saldırıları Önlemi: Sunucuya aşırı miktarda trafik gönderen IP adreslerini engellemek için.
- Lisans veya İçerik Kısıtlamaları: Bazı içerik veya hizmetler belirli coğrafi bölgelerle sınırlı olabilir ve bu bölgeler dışından gelen IP adresleri engellenebilir.
Temsili mimari örnek;

şeklinde ifade edilebilir.
Peki Black List (Siyah Liste) nasıl oluşturulur?
- Otomatik Tespit: Sunucu veya güvenlik duvarı, anormal veya şüpheli aktivite gösteren IP adreslerini otomatik olarak tespit edebilir.
- Manuel Ekleme: Yöneticiler, bilinen kötü niyetli IP adreslerini veya IP aralıklarını manuel olarak siyah listeye ekleyebilir.
- Üçüncü Taraf Kaynaklar: Güvenlik toplulukları ve organizasyonlar, bilinen zararlı IP adreslerinin listelerini yayınlar. Bu listeler, kendi siyah listenize ekleme yapmak için kullanılabilir.
IP engellemesinde ve Black List çözümlerinde dikkat edilmesi gerekenler noktalar;
- Fals Pozitifler: Yanlışlıkla gerçek kullanıcıların IP adreslerini engellemek, kullanıcı deneyimini olumsuz etkileyebilir.
- Dinamik IP Adresleri: Birçok internet servis sağlayıcısı, kullanıcılara dinamik IP adresleri atar. Bu nedenle, bir IP adresini engellemek, o adresin ilerleyen zamanlarda başka birine atanabileceğini göz önünde bulundurmalıdır.
- VPN ve Proxy Kullanımı: Kötü niyetli kullanıcılar, engellenen IP adreslerini aşmak için VPN veya proxy hizmetleri kullanabilir. Bu, IP engellemesinin her zaman etkili olmayabileceği anlamına gelir.
IP engelleme ve siyah liste, web sunucularını ve uygulamalarını korumanın etkili yöntemlerinden biridir. Ancak bu yöntem, dikkatli bir şekilde uygulanmalı ve sürekli olarak gözden geçirilmelidir, böylece gerçek kullanıcıların erişimi yanlışlıkla engellenmez.
User-Agent Yaklaşım Modelleri
User-Agent (Kullanıcı Ajanı); bir web tarayıcısının veya başka bir istemcinin, bir web sunucusuna yaptığı her istekte gönderdiği, o istemciyi tanımlayan bir dizi karakterdir.Bu; genellikle tarayıcının adını, sürümünü ve bazen işletim sistemini içerir.
User-Agent analizi;
- İçerik Uyarlaması: Sunucular, kullanıcı ajanı bilgilerini kullanarak farklı cihazlar veya tarayıcılar için optimize edilmiş içerik sunabilir.
- İstatistik ve Loglama: Web site sahipleri, site trafiğini analiz ederken kullanıcı ajanı bilgilerini kullanabilir.
- Güvenlik: Kötü niyetli botları veya otomatik tarayıcıları tespit etmek için kullanıcı ajanı bilgileri analiz edilebilir.

User-Agent analizi nasıl yapılır?
- Botların Tespiti: Bazı otomatik botlar, kendilerini belirten belirli kullanıcı ajanı dizi setleri kullanır. Bu dizeleri tanımlayarak bu botları tespit edebilirsiniz.
- Sıradışı Dizi Setleri: Beklenmedik veya bilinmeyen kullanıcı ajanı dizeleri, potansiyel olarak kötü niyetli veya istenmeyen trafiği işaret edebilir.
- Sık İstekler: Aynı kullanıcı ajanından gelen anormal derecede sık istekler, otomatik bir scriptin veya botun işareti olabilir.
User-Agent analizinde dikkat edilmesi gereken noktalar;
- Sahte Kullanıcı Ajanları: Kötü niyetli botlar veya scraper’lar, gerçek tarayıcıları taklit eden kullanıcı ajanı dizeleri kullanabilir. Bu, onların tespitini zorlaştırabilir.
- Dinamik İçerik Sunumu: Kullanıcı ajanı bilgisi, içeriği dinamik olarak uyarlamak için kullanıldığında, bu, SEO (Arama Motoru Optimizasyonu) sorunlarına neden olabilir.
- Gizlilik Kaygıları: Kullanıcı ajanı bilgilerinin aşırı derecede kaydedilmesi veya analiz edilmesi, bazı kullanıcılar için gizlilik endişeleri yaratabilir.
User-Agent analizi; web sunucularının ve sitelerinin kullanıcıları ve trafiği hakkında bilgi edinmelerine yardımcı olabilir. Ancak bu analiz, doğru ve etkili bir şekilde yapılmalıdır. Ayrıca, kötü niyetli trafiği tespit etme konusunda tek başına yeterli olmayabilir, bu nedenle diğer güvenlik önlemleriyle birlikte kullanılmalıdır.
WAF (Web Application Firewall) Önlemleri
Web Application Firewall (WAF) (Web Uygulama Güvenlik Duvarı); web uygulamalarını bilinen güvenlik tehditlerinden korumak için özel olarak tasarlanmış bir güvenlik duvarıdır.
WAF, HTTP trafik akışını izler ve analiz eder, böylece kötü niyetli istekleri belirleyip engelleyebilir.
WAF’ın İşlevleri ve Özellikleri:
SQL Enjeksiyonu Engellemesi: WAF, SQL enjeksiyonu ataklarını tespit edebilir ve bu tür istekleri engelleyebilir.
- Çapraz Site Scripting (XSS) Engellemesi: Kötü niyetli scriptlerin web sayfasına enjekte edilmesini önlemek için WAF kullanılır.
- Oturum Kötüye Kullanımını Önleme: WAF, oturum bazlı saldırıları tespit edip engelleyebilir.
- Özel İş Kuralları: WAF, belirli uygulama ihtiyaçlarına göre özelleştirilebilir kurallarla donatılabilir.
- Otomatik Bot ve DDoS Koruma: WAF, otomatik bot trafiğini ve DDoS saldırılarını tespit edip engelleyebilir.
- Trafik İzleme ve Raporlama: WAF, web uygulamasına yönlendirilen trafik hakkında detaylı bilgi toplar ve analiz eder.
- Lokasyon Bazlı Engelleme: WAF ile mevcut trafiğinizi lokasyon bazlı analiz edip, lokasyon bazlı engellemede bulunabilirsiniz.
Temsili mimari örnek;

şeklinde ifade edilebilir.
WAF kullanmanın avantajları ise;
- Gerçek Zamanlı Koruma: WAF, gerçek zamanlı olarak trafik akışını izler ve tehditlere anında yanıt verir.
- Özelleştirilebilirlik: WAF, belirli bir web uygulamasının ihtiyaçlarına göre özelleştirilebilir.
- Merkezi Güvenlik Yönetimi: Büyük ölçekli ağlar ve uygulamalar için WAF, merkezi bir güvenlik yönetimi sağlar.
- Güncellenebilir Tehdit Veritabanı: Modern WAF’lar, yeni tehditleri tanımlamak için sürekli olarak güncellenen tehdit veritabanlarına sahiptir.
- WAF kullanırken dikkat edilmesi gereken noktalar;
- Yanlış Pozitifler: Overly aggressive veya yanlış yapılandırılmış WAF kuralları, meşru trafik veya istekleri yanlışlıkla engelleyebilir.
- Sistem Performans Etkisi: Bazı WAF yapılandırmaları, web uygulamasının performansını olumsuz etkileyebilir.
- Sürekli Gelen Güncellemeler: WAF’ın etkili olması için sürekli olarak güncellenmesi ve yeni tehditlere karşı ayarlanması gerekir.
Web Uygulama Güvenlik Duvarı (WAF); modern web uygulamalarını korumak için kritik bir araçtır. Ancak, doğru bir şekilde yapılandırılmalı, yönetilmeli ve sürekli olarak güncellenmelidir.Bir WAF’ın varlığı, web uygulamasının tamamen güvende olduğu anlamına gelmez, ancak genel güvenlik stratejisinin önemli bir parçasıdır.
Davranış Analizi Modellemesi
Davranışsal Analiz; bir web sitesi veya uygulamada gerçekleşen kullanıcı etkileşimlerini izleyerek, bu etkileşimlerin gerçek bir insan tarafından mı yoksa otomatik bir bot tarafından mı yapıldığını belirlemeye çalışan bir yaklaşım/çözümdür.
Bu; metodoloji olarak, kullanıcının hareketlerini, tıklamalarını, sayfa üzerindeki geçirdiği süreyi ve diğer etkileşimlerini analiz ederek gerçekleştirilmektedir.
Davranışsal analiz yaklaşımında bulunurken alt kısımda yer alan parametreler göz önünde bulundurulmalıdır;
- Sayfa İstek Hızı: Otomatik botlar, insan kullanıcılardan çok daha hızlı bir şekilde sayfa isteklerinde bulunabilmektedir.Bu hızlı istek oranı; bir botun varlığının bir göstergesi olabilir.
Bunu insansı yaklaşım değerleri belirleyerek analiz etmek çözüm sağlayabilir. - Sıradışı Navigasyon Dizileri: Botlar, bir web sitesini gerçek bir kullanıcının yapabileceğinden farklı bir sırayla gezinebilir.Burada insansı davranış modelleri ile takip gerçekleştirilebilir.
- Etkileşimsiz Oturumlar: Eğer bir oturumda herhangi bir mouse hareketi, klavye etkileşimi veya diğer kullanıcı etkileşimleri tespit edilmezse, bu otomatik bir botun işareti olabilir.
Buradaki bot kavramı; iyi – kötü gibi gruplanabilir. (Bknz. Googlebot) - Tekrarlayan İşlem Modelleri: Aynı IP adresi veya kullanıcı ajanından gelen ve belirli bir modeli takip eden tekrarlayan istekler, otomatik scraping faaliyetlerinin bir göstergesi olabilir.
Burada zamansal eylem değerleri üzerinden çözümler üretilebilir. - Mouse Hareketleri: Gerçek kullanıcılar mouse’larını belirli bir şekilde hareket ettirirler.
Bu hareketlerin yönü, hızı ve düzeni, bir botla gerçek bir kullanıcı arasındaki farkı gösteren ipuçları olabilir.
Zor bir analiz parametresi olarak ifade edilmektedir, koordinant yaklaşımı üzerinden çözüm üretilebilir. - Tıklama Davranışı: İnsanların tıklama hızı, tıklama derinliği ve tıklama sıklığı gibi tıklama davranışları, botlarınkinden farklı olabilir.Zaman örüntüleri üzerinden çözümler üretilebilir.
- Klavye Etkileşimleri: Gerçek kullanıcıların yazma hızları, tuş vuruşları ve diğer klavye etkileşimleri, otomatik botlarla kolayca ayırt edilebilir.Zaman örüntüleri üzerinden çözümler üretilebilir.
- Sayfa Geçiş Süreleri: Bir sayfadan diğerine geçiş süreleri, bir botun hızla sayfalar arasında geçiş yapmasıyla gerçek bir kullanıcının daha düşünceli gezinmesi arasında farklılık gösterebilir.
Zaman ve eylem örüntüleri üzerinden çözümler üretilebilir. - Etkileşim Modelleri: İnsan kullanıcıların ve botların etkileşim modelleri genellikle farklıdır.
İnsanlar belirli bir rastgelelik ve düzensizlikle hareket ederken, botlar genellikle belirli bir algoritma veya komuta göre hareket eder.Eylem örüntüleri üzerinden çözümler üretilebilir.
Web Scraping günümüzün en popüler veri elde etme konuları arasında yer alan bir yaklaşım/çözümdür.
Bu yazıda birtakım engelleyici önlemlere yönelik notlarımda yer alan açıklamaları aktarmaya çalıştım.
Umarım faydalı olur.
İyi çalışmalar.





