Merhaba, iyi günler.
Bugün; insan dilini bilgisayarların anlayıp işleyebileceği bir forma dönüştürerek metin analizi, dil modelleme ve duygu analizi gibi alanlarda hem karmaşık dil yapılarını çözümleyen; hem de kullanıcı deneyimini iyileştiren Doğal Dil İşleme (NLP – Natural Language Processing) teknolojisinin mimari yapı ve yaklaşımları üzerine notlarımın devamını [2] paylaşacağım.
İlk bölümde; kural tabanlı sistemlerden derlem çalışmalarına uzanan tarihsel gelişimi, ayrıştırma yapılarını ve istatistiksel NLP’nin yükselişini incelemiştik. Bu bölümde ise; metni bir sınıfa atayan Naive Bayes yaklaşımını, gözlenemeyen dilsel durumları olasılıksal biçimde modelleyen Gizli Markov Modelini ve sözcük dizilerindeki yerel bağlamı sayısallaştıran N-Gram modellerini ele alacağız.
Şimdiden iyi okumalar.
***
Makalede Neler Var ?
- İstatistiksel NLP’de Ortak Mimari Fikir
- Naive Bayes Sınıflandırıcıları
- Naive Bayes Neden “Naive” Olarak Adlandırılır?
- Metin Sınıflandırma Kararı
- Sıfır Olasılık Problemi ve Laplace Düzeltmesi
- Kullanım Alanları, Güçlü Yönler ve Sınırlılıklar
- Gizli Markov Modeli (HMM)
- Markov Zincirlerinden Gizli Durumlara
- HMM’nin Temel Bileşenleri
- HMM’nin İki Temel Varsayımı
- HMM’nin Üç Temel Problemi
- Viterbi Algoritması ile En Olası Durum Dizisi
- Teknik Mantıkta Örneklendirme
- NLP’de Kullanım Alanları ve Sınırlılıklar
- N-Gram Modelleri
- N-Gram Penceresi Nasıl Oluşur?
- Zincir Kuralından Markov Yaklaşımına
- Olasılıkların Derlemden Tahmini
- Veri Seyrekliği, Bilinmeyen N-Gram ve Yumuşatma
- Perplexity ile Dil Modelini Değerlendirmek
- Teknik Mantıkta Örneklendirme
- N-Gram Modellerinin Güçlü ve Zayıf Yönleri
- Üç Yaklaşımın Karşılaştırılması
İstatistiksel NLP’de Ortak Mimari Fikir
Kural tabanlı sistemlerde bir dil uzmanı, sistemin hangi durumda nasıl davranacağını önceden tanımlamaktaydı. İstatistiksel yaklaşımda ise; bu kuralların önemli bir bölümü veriden, gözlem sıklıklarından ve olasılık dağılımlarından çıkarılmaktadır. Böylece sistem, “bu sözcük kesinlikle bu sınıfa aittir” biçimindeki katı bir karardan ziyade; “mevcut kanıtlar altında en olası sınıf veya dizi hangisidir?” sorusuna yanıt üretmektedir.
Naive Bayes, HMM ve N-Gram modelleri farklı problemlere odaklansa da aynı matematiksel zeminde buluşmaktadır: geçmiş gözlemlerden olasılık tahmini yapmak, bu olasılıkları bir karar kuralı içinde birleştirmek ve belirsizliği ölçülebilir hale getirmek.
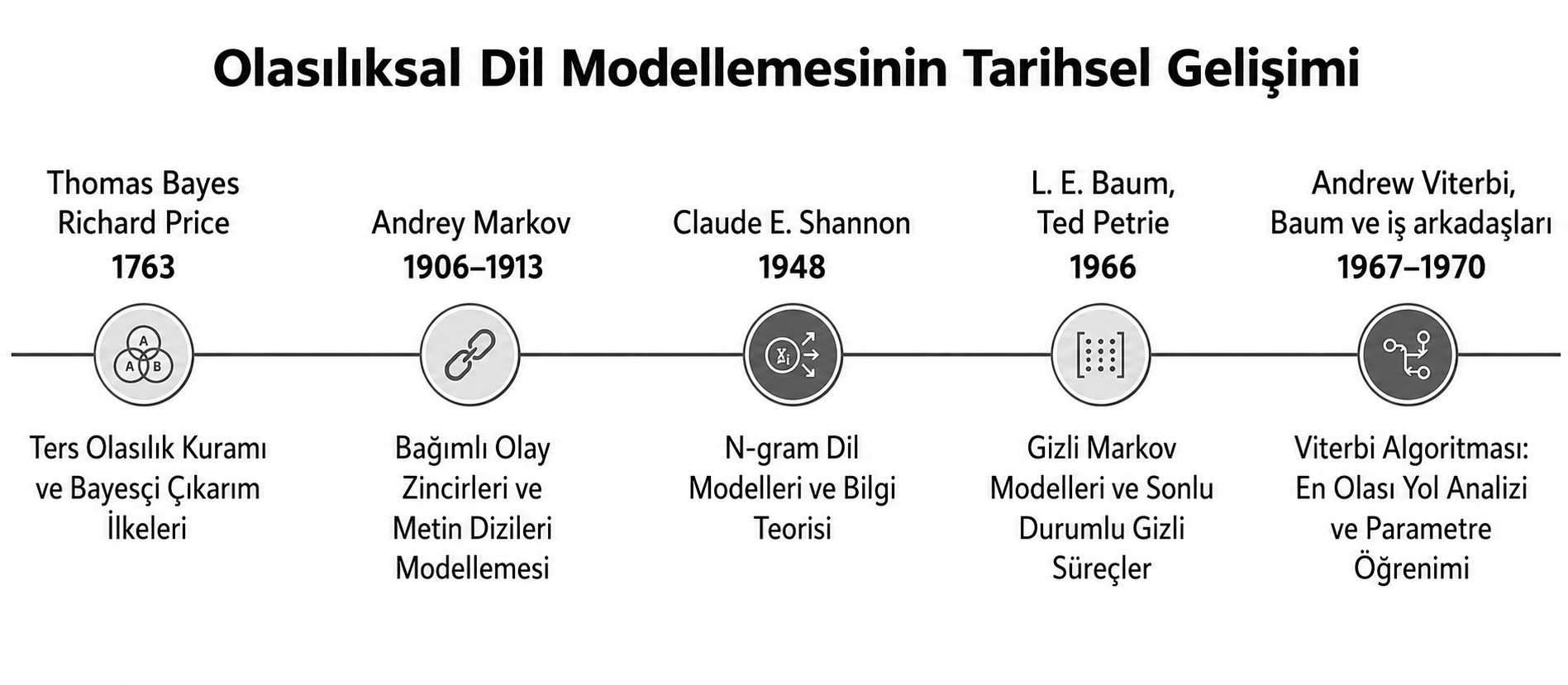
Tarihsel atıf konusunda önemli not
Naive Bayes, HMM veya N-Gram için tek bir “mucit” adı vermek yanıltıcıdır. Bu modeller; Bayesçi olasılık, Markov zincirleri, bilgi kuramı, sonlu durumlu süreçler ve dinamik programlama çalışmalarının zaman içinde birleşmesiyle bugünkü biçimine ulaşmıştır.
Naive Bayes Sınıflandırıcıları
Naive Bayes Sınıflandırıcıları, adını; 18.yüzyılda yaşamış İngiliz matematikçi ve ilahiyatçı Thomas Bayes’ten almaktadır. Bayes; koşullu olasılıklar üzerine yaptığı çalışmalarla, modern olasılık teorisinin temel taşlarını atmıştır.

Naive Bayes Sınıflandırıcıları
Koşullu Olasılık (Conditional Probability); bir olayın (A) olma şansının, başka bir olayın (B) gerçekleştiği bilgisi ışığında nasıl değiştiğini tanımlamaktadır.
Matematiksel olarak ise şöyle ifade edilmektedir;
P(A|B) = P(A ∩ B) / P(B), (P(B) ≠ 0)
P(A|B): “B gerçekleştiğinde A’nın olasılığı”
P(A ∩ B): “A ve B’nin birlikte gerçekleşme olasılığı”
P(B): “B’nin gerçekleşme olasılığı”
Burada; P(A | B), B gerçekleştiğinde A’nın olasılığını; P(A ∩ B), A ve B’nin birlikte gerçekleşme olasılığını; P(B) ise B olayının gerçekleşme olasılığını ifade etmektedir.
Bayes Teoremi ise koşullu olasılığın iki farklı yönden yazılmasını birleştirir ve gözlenen kanıt üzerinden hipotez olasılığını günceller:
*Posterior = Likelihood × Prior / Evidence
Bu teori, Bayes’in ölümünden sonra; Richard Price tarafından 1763 yılında Royal Society’ye sunulan;
An Essay towards solving a Problem in the Doctrine of Chances
Şans Doktrininde Bir Sorunu Çözmeye Yönelik Bir Deneme
adlı, Galli asıllı bir filozof, matematikçi, iktisatçı ve Unitarı papaz Richard Price’ın (1723–1791) sunumunda yer aldı. Price’ın katkısı yalnızca metni yayıma hazırlamakla sınırlı değildir; çalışmanın deneysel felsefe ve tümevarımsal akıl yürütme açısından önemini açıklayan kapsamlı bir giriş de eklemiştir.
İlgili Makale: https://bayes.wustl.edu/Manual/an.essay.pdf
Price’a göre; Bayes’in çalışması hem deneysel felsefe hem de matematiksel olasılık kuramı açısından önemli bir boşluğu doldurmaktaydı.
Naive Bayes Neden “Naive” Olarak Adlandırılır?
Metin sınıflandırmada bir belge; sözcükler, karakter dizileri veya farklı özelliklerden oluşan bir gözlem kümesi olarak düşünülebilir. Bir belgenin sınıfını doğrudan hesaplamak, özellikler arasındaki bütün bağımlılıkları modellemeyi gerektirdiği için oldukça maliyetlidir. Naive Bayes; sınıf bilindiğinde özelliklerin birbirinden koşullu olarak bağımsız olduğunu varsayarak bu hesabı sadeleştirir.
Özellikler, sınıf c verildiğinde koşullu bağımsız kabul edilir.
Gerçek dilde bu varsayım bütünüyle doğru değildir. Örneğin; “çok iyi” ifadesindeki “çok” ve “iyi” sözcükleri birbirinden bağımsız değildir. Ancak varsayımın matematiksel sadeliği; özellikle veri miktarının sınırlı olduğu, yüksek boyutlu ve seyrek metin temsillerinde güçlü bir başlangıç modeli sunmaktadır.
Metin Sınıflandırma Kararı
Bir belge d için en olası sınıf; sınıfın önsel olasılığı P(c) ile belgenin o sınıf altında görülme olasılığı P(d | c) çarpılarak seçilir. P(d) bütün sınıflarda aynı olduğu için karar aşamasında paydadan çıkarılabilir.
Çok sayıda küçük olasılığın çarpılması, sayısal taşma-altı (underflow) problemine neden olabilir. Bu sebeple pratik uygulamalarda çarpım yerine logaritmik toplam kullanılmaktadır;
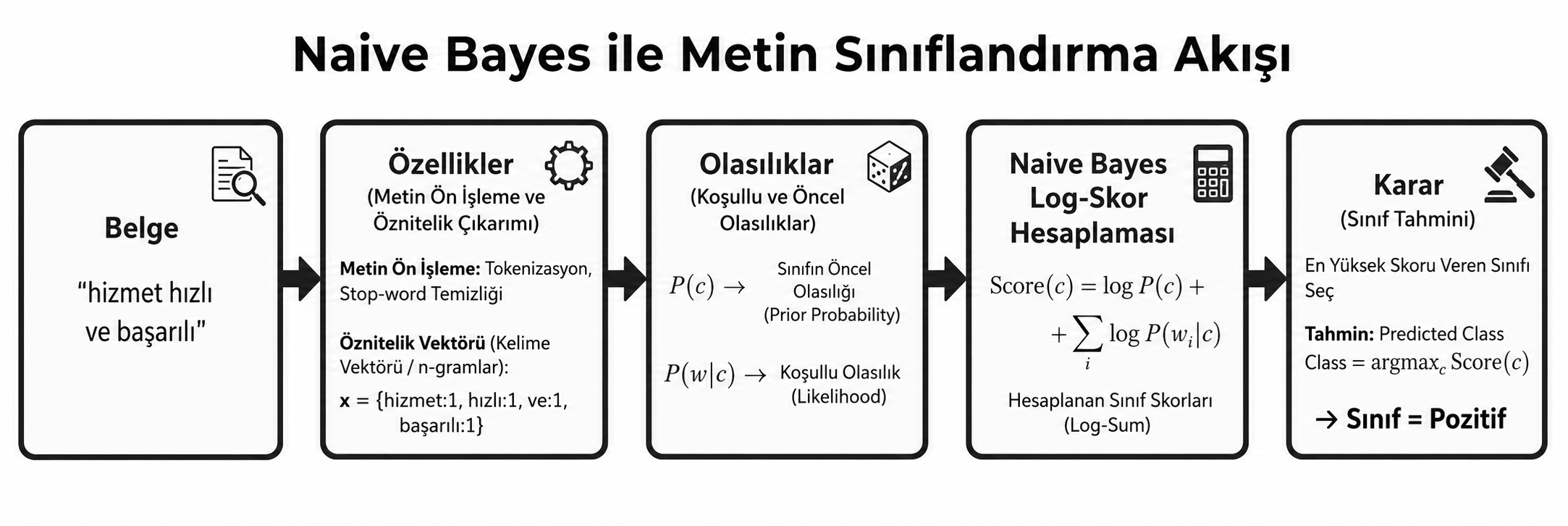
Sıfır Olasılık Problemi ve Laplace Düzeltmesi
Eğitim kümesinde hiç görülmeyen bir sözcüğün olasılığı sıfır olarak hesaplanırsa, bütün sınıf skoru sıfıra düşmektedir. Bu problem; sözcük sayımlarına küçük bir α değeri ekleyen Additive/Laplace Smoothing yöntemiyle azaltılabilir.
α = 1 seçimi klasik Laplace düzeltmesidir; |V| sözlük büyüklüğüdür.
Bu düzeltme; görülmeyen sözcüklere küçük fakat sıfır olmayan bir olasılık atarken, eğitim verisinde sık görülen sözcüklerin ağırlığını da korumaktadır.
Temsili örnek (Python ile.);
from collections import Counter, defaultdict
from math import log
train = [
("pozitif", "ürün hızlı ve başarılı"),
("pozitif", "hizmet hızlı ve güvenilir"),
("negatif", "ürün yavaş ve sorunlu"),
("negatif", "hizmet gecikmeli ve başarısız"),
]
class_docs = Counter()
word_counts = defaultdict(Counter)
total_words = Counter()
vocabulary = set()
for label, text in train:
tokens = text.lower().split()
class_docs[label] += 1
word_counts[label].update(tokens)
total_words[label] += len(tokens)
vocabulary.update(tokens)
def predict(text, alpha=1.0):
tokens = text.lower().split()
scores = {}
for label in class_docs:
score = log(class_docs[label] / len(train))
for token in tokens:
numerator = word_counts[label][token] + alpha
denominator = total_words[label] + alpha * len(vocabulary)
score += log(numerator / denominator)
scores[label] = score
return max(scores, key=scores.get), scores
label, scores = predict("hizmet hızlı ve başarılı")
print(label)
print(scores)Beklenen çıktı: pozitif {‘pozitif’: -8.6711, ‘negatif’: -10.4629}
Model çıktısı nasıl okunmalıdır?
Log skorlarının mutlak büyüklüğünden çok, sınıflar arasındaki göreli fark önemlidir. Bu örnekte pozitif sınıfın skoru daha yüksek olduğu için cümle “pozitif” olarak etiketlenmektedir.
Kullanım Alanları, Güçlü Yönler ve Sınırlılıklar
| Boyut | Değerlendirme |
| Kullanım alanları | Spam filtreleme, duygu analizi, konu sınıflandırma, belge yönlendirme, basit niyet tespiti. |
| Güçlü yönü | Hızlı eğitilir; az veriyle çalışabilir; yüksek boyutlu seyrek metinlerde güçlü bir taban modelidir. |
| Yorumlanabilirlik | Sınıf önselleri ve sözcük olasılıkları incelenebilir; kararın hangi sözcüklerden etkilendiği görülebilir. |
| Temel sınırlılık | Sözcük sırası ve özellik bağımlılıkları çoğunlukla göz ardı edilir; ironi, olumsuzluk kapsamı ve uzun bağlamı anlamakta zorlanır. |
| Uygulama riski | Dengesiz sınıflar, veri sızıntısı, nadir sözcükler ve alan değişimi performansı yanıltabilir. |
Naive Bayes’in modern metin sistemlerindeki önemi yalnızca tek başına sağladığı başarıdan kaynaklanmamaktadır. Model; daha karmaşık yöntemlerin anlamlı biçimde değerlendirilmesi için güçlü bir baseline oluşturur. Bunun yanı sıra; sınıflandırma probleminin olasılıksal düşünceyle nasıl kurulacağını açık ve denetlenebilir biçimde göstermektedir.
Gizli Markov Modeli (HMM)
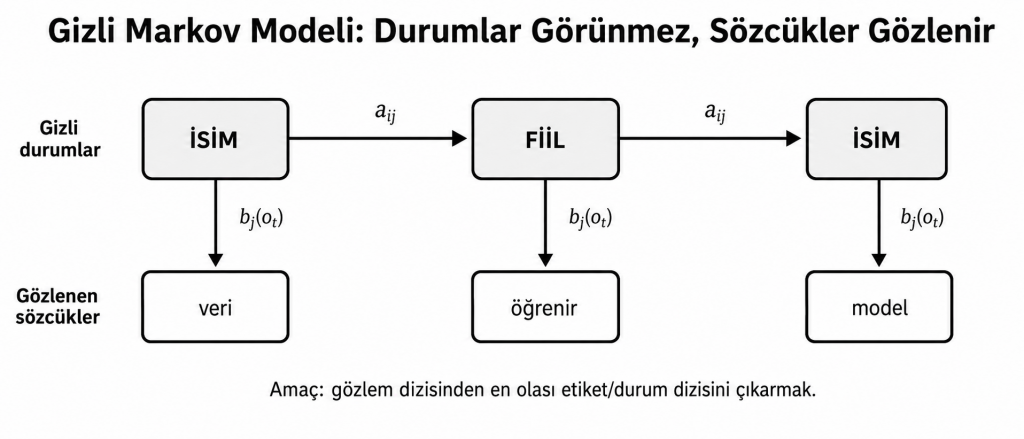
Gizli Markov Modeli (Hidden Markov Model – HMM); zaman veya sıra boyunca ilerleyen bir sistemde, doğrudan gözlenemeyen durumları; gözlenebilen çıktılar üzerinden olasılıksal biçimde tahmin eden bir modeldir. NLP açısından gözlenen değerler çoğunlukla sözcükler, ses birimleri veya karakterlerdir. Gizli durumlar ise; sözcük türleri, konuşma durumu, fonemler, varlık etiketleri veya anlamsal sınıflar olabilir.
Markov Zincirlerinden Gizli Durumlara
Modelin tarihsel kökü, Rus matematikçi Andrey Andreyeviç Markov’un bağımlı olay dizileri üzerine yaptığı çalışmalara uzanmaktadır. Markov; ardışık olayların bütünüyle bağımsız olmak zorunda olmadığını, belirli koşullarda gelecek durumun yakın geçmişteki duruma bağlı olarak modellenebileceğini göstermiştir. 1913 tarihli çalışmasında Puşkin’in “Yevgeni Onegin” metnindeki 20.000 harfi ünlü-ünsüz dizileri üzerinden incelemesi, Markov yaklaşımının dil verisine uygulanan erken örneklerinden biridir.
Bugünkü HMM kuramının temel biçimi ise Leonard E. Baum ve Ted Petrie’nin 1966 tarihli sonlu durumlu Markov zincirlerinin olasılıksal fonksiyonlarına ilişkin çalışmasıyla sistematikleşmiştir. Andrew J. Viterbi’nin 1967’de kod çözme problemi için geliştirdiği dinamik programlama algoritması, daha sonra HMM’lerde en olası gizli durum dizisini bulmak için kullanılmıştır. Baum ve çalışma arkadaşlarının 1970 tarihli makalesi ise model parametrelerinin gözlemlerden yeniden tahmin edilmesine temel oluşturmuştur.
HMM’nin Temel Bileşenleri
Bir HMM genellikle λ = (A, B, π) parametreleriyle tanımlanmaktadır;
- Q = {q₁, q₂, …, qₙ}: Modeldeki gizli durum kümesi.
- A = [aᵢⱼ]: i durumundan j durumuna geçiş olasılıklarını içeren matris.
- B = [bⱼ(oₜ)]: j durumunun oₜ gözlemini üretme/yayma olasılığı.
- π = [πᵢ]: Dizinin i durumunda başlama olasılığı.
Durum geçiş olasılığı;
Gözlem/yayılım olasılığı;
HMM’nin İki Temel Varsayımı
1.Birinci dereceden Markov varsayımı: Mevcut durumun olasılığı, bütün geçmiş yerine yalnızca bir önceki duruma bağlıdır.
2.Çıktı bağımsızlığı varsayımı: Mevcut gözlem, mevcut gizli durum bilindiğinde diğer durum ve gözlemlerden bağımsız kabul edilir.
Bu varsayımlar, doğal dilin bütün karmaşıklığını eksiksiz temsil etmez. Ancak olası durum dizilerinin üstel büyümesini kontrol altına alarak hesaplamayı dinamik programlama ile yönetilebilir hale getirir.
HMM’nin Üç Temel Problemi
| Problem | Soru | Temel Algoritma |
| 1. Değerlendirme | Belirli bir gözlem dizisinin model altında olasılığı nedir? P(O | λ) | Forward Algoritması |
| 2. Kod Çözme | Gözlemleri üretmiş olması en muhtemel gizli durum dizisi hangisidir? | Viterbi Algoritması |
| 3. Öğrenme | A, B ve π parametreleri yalnızca gözlemlerden nasıl tahmin edilir? | Forward–Backward / Baum–Welch |
Viterbi Algoritması ile En Olası Durum Dizisi
Bir T uzunluklu gözlem dizisi ve N adet gizli durum için bütün durum yollarını tek tek denemek Nᵀ olasılığı incelemeyi gerektirir. Viterbi algoritması; her zaman adımında yalnızca o hücreye ulaşan en güçlü yolu saklayarak aynı alt problemlerin tekrar hesaplanmasını önler.
Algoritma yalnızca en yüksek olasılığı saklamakla yetinmez; her hücre için bir geri işaretçi (backpointer) tutar. Son zaman adımındaki en yüksek skordan geriye doğru yüründüğünde, en olası gizli durum dizisi elde edilir.
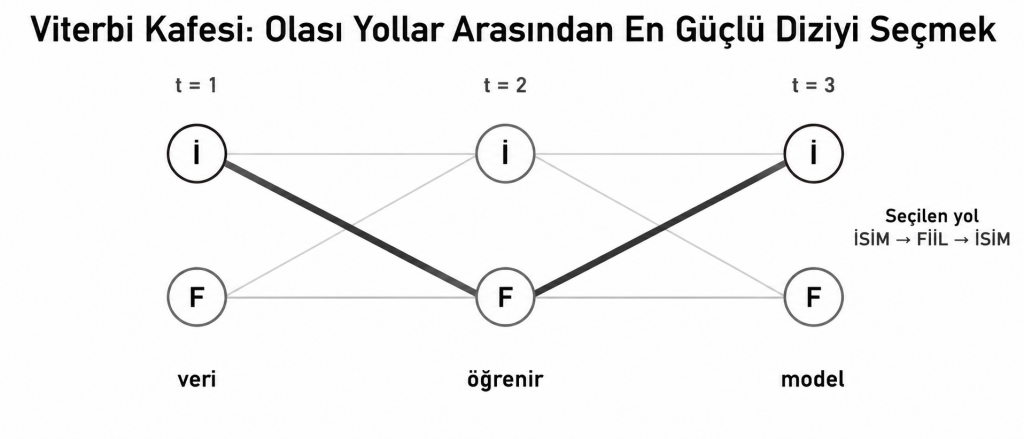
Teknik Mantıkta Örneklendirme
Aşağıdaki kod; iki gizli sözcük türü durumu için Viterbi çözümünü sadeleştirilmiş biçimde gerçekleştirmektedir. Gerçek bir POS etiketleyicide durum ve gözlem sözlükleri çok daha geniş olacak; bilinmeyen sözcükler için yumuşatma veya morfolojik özellikler kullanılacaktır.
Temsili örnek (Python ile.);
from math import log
states = ["ISIM", "FIIL"]
start = {"ISIM": 0.60, "FIIL": 0.40}
transition = {
"ISIM": {"ISIM": 0.30, "FIIL": 0.70},
"FIIL": {"ISIM": 0.60, "FIIL": 0.40},
}
emission = {
"ISIM": {"veri": 0.50, "öğrenir": 0.10, "model": 0.40},
"FIIL": {"veri": 0.10, "öğrenir": 0.80, "model": 0.10},
}
def viterbi(observations):
scores = [{}]
paths = {}
for state in states:
scores[0][state] = log(start[state]) + log(emission[state][observations[0]])
paths[state] = [state]
for t in range(1, len(observations)):
scores.append({})
new_paths = {}
for current in states:
candidates = []
for previous in states:
score = (scores[t-1][previous]
+ log(transition[previous][current])
+ log(emission[current][observations[t]]))
candidates.append((score, previous))
best_score, best_previous = max(candidates)
scores[t][current] = best_score
new_paths[current] = paths[best_previous] + [current]
paths = new_paths
last_state = max(scores[-1], key=scores[-1].get)
return paths[last_state], scores[-1][last_state]
print(viterbi(["veri", "öğrenir", "model"]))Beklenen çıktı: ([‘ISIM’, ‘FIIL’, ‘ISIM’], -4.337…)
NLP’de Kullanım Alanları ve Sınırlılıklar
| Alan | HMM’nin Rolü |
| Sözcük türü etiketleme | Sözcükleri gözlem, POS etiketlerini gizli durum olarak ele alır. |
| Konuşma tanıma | Akustik özelliklerden fonem veya alt-sözcük durum dizilerini çıkarır. |
| Adlandırılmış varlık tanıma | Token dizisi üzerinden kişi, kurum, konum gibi etiket dizilerini tahmin eder. |
| Diyalog modelleme | Gözlenen ifadelerden gizli konuşma eylemi/diyalog durumlarını çıkarabilir. |
| Segmentasyon | Metin veya ses akışını olasılıksal durum sınırlarına ayırabilir. |
HMM; yorumlanabilir, matematiksel olarak açık ve dinamik programlama ile verimli bir modeldir. Buna karşın; uzun mesafeli bağımlılıkları sınırlı biçimde temsil eder, özelliklerin bağımsızlığı konusunda güçlü varsayımlar yapar ve zengin bağlamı tek bir gizli durum üzerinden açıklamaya çalışır. Bu sınırlılıklar; Koşullu Rastgele Alanlar (CRF), RNN/LSTM ağları ve daha sonra Transformer tabanlı dizisel modellerin yükselişini hazırlayan etkenlerden biri olmuştur.
N-Gram Modelleri
N-Gram; bir metin veya sembol dizisi içindeki ardışık N öğeden oluşan parçayı ifade etmektedir. Öğeler; sözcük, karakter, hece veya alt-sözcük birimi olabilir. Sözcük tabanlı bir modelde N = 1 Unigram, N = 2 Bigram, N = 3 ise Trigram olarak adlandırılır.
N-Gram yaklaşımının düşünsel kökü Markov zincirlerine uzanırken; Claude E. Shannon’ın 1948 tarihli “A Mathematical Theory of Communication” çalışması, doğal dile farklı derecelerde yaklaşan harf ve sözcük dizilerini digram, trigram ve genel n-gram olasılıklarıyla tartışan temel kaynaklardan biri olmuştur. Shannon; bir sembolün seçiminin önceki bir veya iki sembole bağlı hale getirildiğinde, üretilen dizilerin dilin istatistiksel yapısına giderek daha fazla benzediğini göstermiştir.
İlgili Makale: A Mathematical Theory of Communication
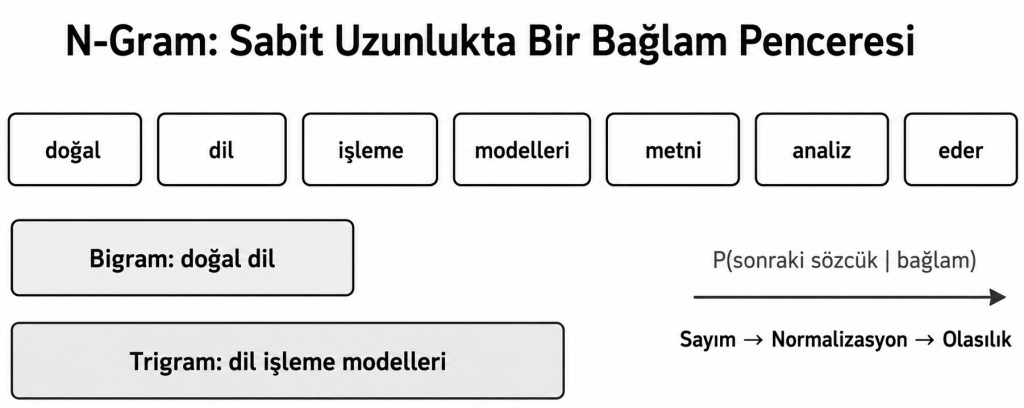
N-Gram Penceresi Nasıl Oluşur?
“Doğal dil işleme modelleri metni analiz eder” cümlesi üzerinden örneklendirecek olursak;
- Unigram: doğal | dil | işleme | modelleri | metni | analiz | eder
- Bigram: doğal dil | dil işleme | işleme modelleri | modelleri metni | metni analiz | analiz eder
- Trigram: doğal dil işleme | dil işleme modelleri | işleme modelleri metni | modelleri metni analiz | metni analiz eder
Zincir Kuralından Markov Yaklaşımına
Bir cümlenin tam olasılığı, olasılık zincir kuralıyla her sözcüğün kendisinden önceki bütün sözcüklere koşullu olasılıklarının çarpımı olarak yazılabilir:
Ancak bütün geçmişi hesaba katmak; veri seyrekliği ve hesaplama maliyeti nedeniyle pratik değildir. N-Gram modeli, yalnızca son N−1 sözcüğün yeterli bağlam sağladığını varsayar:
Bigram modelinde cümle olasılığı yaklaşık olarak aşağıdaki biçimde hesaplanmaktadır:
Olasılıkların Derlemden Tahmini
Maksimum Olabilirlik Tahmini (Maximum Likelihood Estimation – MLE), bir N-Gram’ın görülme sayısını bağlamın toplam görülme sayısına bölmektedir. Bigram için;
Örneğin bir derlemde “doğal dil” bigramı 80 kez, “doğal” sözcüğü toplam 100 kez bir sonraki sözcüğe bağlanmışsa; P(dil | doğal) = 80 / 100 = 0,80 olarak tahmin edilir. Bu değer, “doğal” sözcüğünden sonra “dil” sözcüğünün gelmesine modelin atadığı koşullu olasılıktır.
Veri Seyrekliği, Bilinmeyen N-Gram ve Yumuşatma
N büyüdükçe model daha fazla bağlam görür; fakat olası N-Gram sayısı da hızla artar. Eğitim derleminde bulunmayan tek bir N-Gram’ın olasılığının sıfır olması, bütün cümle olasılığını sıfıra indirebilir. Bu nedenle klasik dil modellemede yumuşatma (smoothing) yöntemleri kritik öneme sahiptir.
- Add-k / Laplace: Bütün sayımlara küçük bir k değeri ekler.
- Backoff: Yüksek dereceli N-Gram bulunamadığında daha kısa bağlama geri döner.
- Interpolation: Unigram, bigram ve trigram olasılıklarını ağırlıklı biçimde birleştirir.
- Kneser–Ney: Yalnızca sözcük sıklığını değil, sözcüğün farklı bağlamlarda ne kadar çeşitlendiğini de dikkate alan güçlü bir klasik yöntemdir.
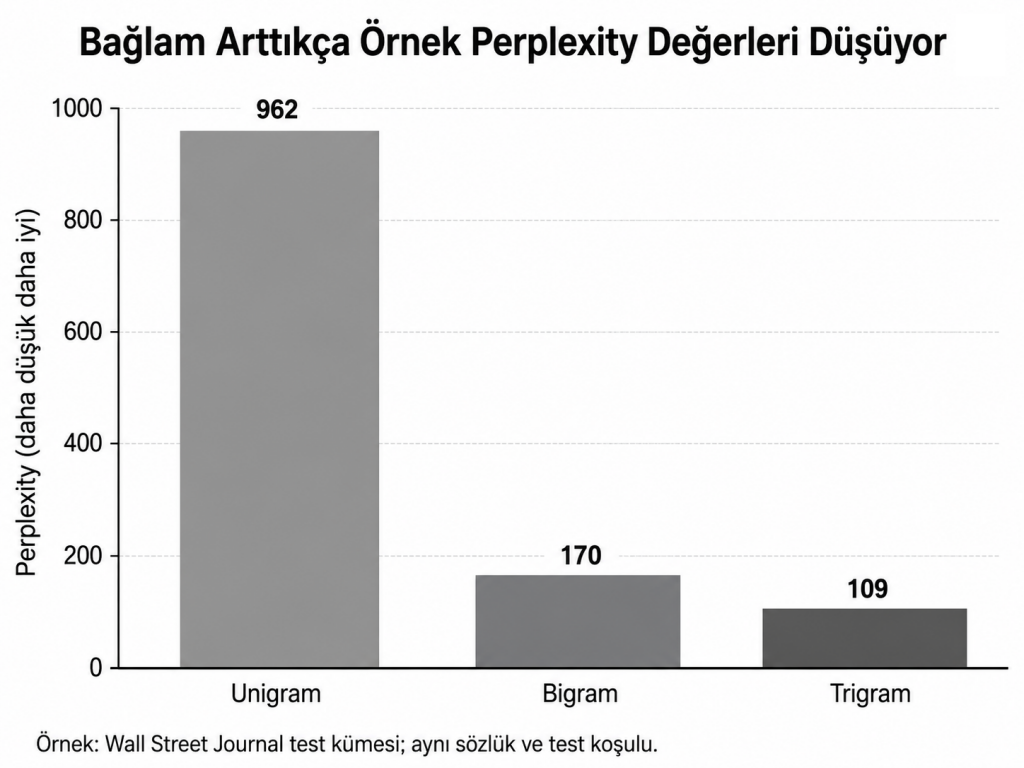
Perplexity ile Dil Modelini Değerlendirmek
Perplexity; modelin test dizisi karşısında ne kadar “şaşırdığını” ölçen içsel bir değerlendirme metriğidir. Test dizisine yüksek olasılık veren modelin perplexity değeri daha düşük olur.
Jurafsky ve Martin’in aynı sözlük ve test koşulu altında sunduğu Wall Street Journal örneğinde; unigram için 962, bigram için 170 ve trigram için 109 perplexity değeri raporlanmaktadır. Bu sonuç, daha geniş yerel bağlamın test dizisini tahmin etme gücünü artırabildiğini göstermektedir. Bununla birlikte düşük perplexity, her zaman son uygulamada daha yüksek kalite garantisi değildir; modelin konuşma tanıma, çeviri veya sınıflandırma gibi gerçek görevlerde ayrıca değerlendirilmesi gerekir.
Teknik Mantıkta Örneklendirme
Aşağıdaki temsili kod; cümle başlangıç ve bitiş işaretlerini ekleyerek bigram sayımlarını oluşturmakta, ardından verilen bir bağlam için en sık görülen sonraki sözcükleri listelemektedir.
Temsili örnek (Python ile.);
from collections import Counter, defaultdict
corpus = [
"doğal dil işleme metni analiz eder",
"doğal dil işleme dili modeller",
"doğal dil modelleri metni üretir",
]
bigram_counts = defaultdict(Counter)
context_counts = Counter()
for sentence in corpus:
tokens = ["<s>"] + sentence.lower().split() + ["</s>"]
for left, right in zip(tokens, tokens[1:]):
bigram_counts[left][right] += 1
context_counts[left] += 1
def next_words(context):
results = []
for word, count in bigram_counts[context].most_common():
probability = count / context_counts[context]
results.append((word, probability))
return results
print(next_words("dil"))Beklenen çıktı: [(‘işleme’, 0.6667), (‘modelleri’, 0.3333)]
N-Gram Modellerinin Güçlü ve Zayıf Yönleri
| Boyut | Değerlendirme |
| Güçlü yön | Basit, hızlı, açıklanabilir ve paralelleştirilebilir; büyük metin koleksiyonlarında etkili bir klasik taban modelidir. |
| Bağlam | Yakın sözcük birlikteliklerini iyi yakalar; yazım denetimi, otomatik tamamlama ve konuşma tanımada yararlıdır. |
| Temel sınırlılık | Bağlam penceresi sabittir; uzak bağımlılıkları, anlamsal benzerliği ve yeni bileşimleri zayıf geneller. |
| Kaynak ihtiyacı | N arttıkça bellek ve veri ihtiyacı büyür; sözcük dağarcığı genişledikçe seyrekleşme hızlanır. |
| Modern rol | Sinirsel dil modellerinin öncesinde ana yaklaşım; günümüzde ise hibrit sistemlerde, geri dönüş modelinde ve hızlı baseline olarak değerlidir. |
Üç Yaklaşımın Karşılaştırılması
Naive Bayes, HMM ve N-Gram aynı dönemin istatistiksel düşüncesini temsil etse de çözmeye çalıştıkları problem farklıdır. Birincisi belgeyi sınıfa atar; ikincisi bir gözlem dizisinin arkasındaki gizli durum dizisini çıkarır; üçüncüsü ise sınırlı bağlamdan bir dizinin veya sonraki öğenin olasılığını tahmin eder.
| Yaklaşım | Temel Soru | Ana Olasılık | Tipik NLP Görevi | Bağlam Yapısı |
| Naive Bayes | Bu belge hangi sınıfa ait? | P(c|d) | Duygu, spam, konu sınıflandırma | Bag-of-Words; sıra çoğunlukla yok |
| HMM | Bu gözlemleri hangi gizli durumlar üretti? | P(Q,O|λ) | POS, konuşma tanıma, dizi etiketleme | Durum geçişleri ve yayılımlar |
| N-Gram | Bu bağlamdan sonra ne gelir? | P(wᵢ|wᵢ₋ₙ₊₁…wᵢ₋₁) | Dil modelleme, tamamlama, yazım/ASR | Sabit uzunluklu yerel pencere |
Mimari açıdan ortak çıkarım
Bu üç model, dil problemini “özellik veya durumların olasılıksal bileşimi” olarak ele alır. Modern sinirsel modeller farklı temsil öğrenme yöntemleri kullansa da; önsel, koşullu olasılık, dizi olasılığı, kod çözme ve model değerlendirme gibi kavramlar günümüzde de merkezi önemini korumaktadır.
İstatistiksel NLP; dilin katı kurallarla açıklanamayacak ölçüde değişken olduğunu kabul ederek, gözlem ve belirsizliği modelin merkezine yerleştirmiştir. Naive Bayes; sözcük kanıtlarını sınıf olasılıklarıyla birleştirerek metin sınıflandırmanın en yalın olasılıksal örneklerinden birini sunar. Gizli Markov Modeli; doğrudan göremediğimiz dilsel durumları, gözlenen diziler üzerinden çıkarabilmemizi sağlar. N-Gram modelleri ise; dildeki yakın bağlam ilişkilerini sayım ve koşullu olasılık üzerinden ölçülebilir hale getirir.
Bu modellerin ortak başarısı; her birinin bütün dil problemini tek başına çözmesinden değil, karmaşık bir problemi hesaplanabilir alt varsayımlara ayırmasından kaynaklanmaktadır. Koşullu bağımsızlık, Markov varsayımı ve sabit bağlam penceresi gerçek dili eksiksiz temsil etmese de; modern NLP’nin sınıflandırma, dizi modelleme ve dil modeli kavramlarını biçimlendiren temel mimari düşünceleri ortaya koymuştur.
Bugün Transformer ve büyük dil modelleriyle çalışırken dahi; log-olasılık, dizisel kod çözme, yumuşatma, perplexity, önsel bilgi ve bağlam bağımlılığı gibi kavramların izleri doğrudan bu istatistiksel yaklaşımlarda görülmektedir. Bu nedenle klasik modelleri anlamak; yalnızca tarihsel bir inceleme değil, modern sistemlerin hangi problemleri hangi yöntemlerle aştığını daha doğru yorumlayabilmek için güçlü bir teknik altyapıdır.
İstatistiksel modellerin sunduğu bu temel üzerinde; sözcükleri yalnızca sayım tablosu veya ayrık kimlikler olarak değil, sürekli vektör uzaylarında temsil eden sinirsel yaklaşımlara geçeceğiz.
Bir sonraki yazımızda;
- Dağıtımsal Sözcük Temsilleri ve Word Embeddings yaklaşımı,
- Word2Vec ve GloVe ile anlamsal yakınlık fikri,
- Feed-Forward Sinirsel Dil Modelleri,
- RNN, LSTM ve GRU ile uzun süreli bağımlılıkların modellenmesi,
- Encoder–Decoder yapıları ve Attention mekanizmasına geçiş
başlıkları üzerinden, istatistiksel NLP’den sinirsel dil modellerine uzanan mimari dönüşümü incelemeye devam edeceğiz.
İyi çalışmalar…