

Python, Veri Bilimi / 21 Ocak 2023 / Miraç ÖZTÜRK
Merhaba iyi günler.
Bugün; popülaritesi gün geçtikçe yükselen, birçok makine öğrenmesi-yapay zeka temelli uygulamalarda açık ara ön planda olan, veri madenciliği-bilimsel analiz çözümlemelerinde esnek çözümlemeler sunan, hızlı ve çevik yapısı ile kullanıcıların gözdesi olarak yer edinmiş olan Python dili üzerinde bir modelin performansının nasıl olduğunun tahmin edilmesi için kullanılan Çapraz Doğrulama – Cross Validation çözümlerini inceliyor olacağım.
Şimdiden iyi okumalar.
Makalede Neler Var ?
Çapraz Doğrulama - Cross Validation Nedir?
Çapraz Doğrulama (Cross Validation); bir modelin eğitim verileriyle elde edilen performansının gerçek dünya verileriyle nasıl olacağını tahmin etmek için kullanılan bir tekniktir.Bu teknik; eğitim verileriyle modeli eğitirken, geri kalan verileri (doğrulama verileri) kullanarak modelin performansını değerlendirir.
*Model başarısı değerlendirmesi.
Bu sayede; modelin gerçek dünya verileriyle nasıl performans göstereceği hakkında daha doğru bir fikir edinilir.
Bu teknikğin kendi içinde bulunan birkaç ayrımı ve method/yöntemi bulunmaktadır.
Bunlar;
Çapraz Doğrulama - Cross Validation Metodları/Yöntemleri
Çapraz doğrulama metodları/yöntemleri kaynaklar ve yayınlanmış çalışmalar incelendiğinde genellikle iki ana grupta toplanmaktadır;
- Parametrik Yöntemler:Bu yöntemlerde veri setindeki verilerin dağılımının belli bir formülle ifade edilebildiği varsayılır.Örneğin; Holdout ve Simple Cross Validation gibi yöntemler veri setinin belirli bir yüzdesini test verisi, geri kalanını ise eğitim verisi olarak kullanır.
- Non-Parametrik (Parametrik Olmayan) Yöntemler:Bu yöntemler, veri setindeki verilerin dağılımının belli bir formülle ifade edilemediği varsayılır.Örneğin; K-Fold Cross Validation, Leave One Out Cross Validation, Time Series Cross Validation, Bootstrap gibi yöntemler veri setinin tümünü eğitim ve test için kullanır.
Ayrıca; çapraz doğrulama yöntemleri veri seti kullanımı bakımından statik ve dinamik olarakta sınıflandırılabilir.
Statik yöntemler veri setini bir kere bölüp, aynı veri setini kullanırken; Dinamik yöntemler veri setini tekrar tekrar bölüp, farklı varyasyondaki veri setleri olarak kullanır.
Çapraz doğrulama teknikleri veri kümesinin nasıl bölüneceğine;
- Rastgele bölünürse; Randomized Cross Validation,
- Zaman serisi olarak bölünürse; Time Series Cross Validation,
- Şekline göre bölünürse (“k” eşit parçaya); K-Fold Cross Validation,
- Sadece bir veri noktası doğrulama verisi olarak kullanır ise, Leave One Out Cross Validation,
- Sadece bir kez bölünürse, Simple Cross Validation,
- Birden fazla kez bölünürse, Repeated Cross Validation
- Veri seti küçük ise, Boostrap Cross Validation
Meşhur ve vazgeçilmez olan Iris Veri setini kullanarak, bu başlıklara (Yöntemlere) özet manada değinmeye çalışalım;
Hatırlatma:İlgili veri setine ait csv. uzantılı dosyasına buradan ulaşabilirsiniz.

Iris Veri Seti 3 Iris bitki türüne (Iris Setosa, Iris Virginica ve Iris Versicolor) ait, her bir türden 50 örnek olmak üzere toplam 150 örnek sayısına sahip bir veri setidir.
Iris Veri Seti içerisinde;
Sınıflar (Türler);
- Iris Setosa,
- Iris Versicolor,
- Iris Virginica.
Veri Özellikleri (Ortak Özellikler);
- Sepal Uzunluk (cm),
- Sepal Genişlik (cm),
- Petal Genişliği (cm)
- Petal Uzunluk (cm).
özellik ve değerleri bulunmaktadır.
K-Fold
K-Fold Cross-Validation (K Katmanlı Çapraz Doğrulama) yöntemi; veri kümenizi “k” eşit parçaya bölerek, her bir parça için tek tek doğrulama verisi oluşturup işlemde bulunmaktadır.Böylece her veri noktası en az bir kez doğrulama verisi olarak kullanılmış olup, modelin genel performansı daha doğru değerlendirilebilir.
Buradaki bölünme değeri olan “k” değeri; genellikle k=5 veya k=10 olarak seçilmektedir.
Örneğin; veri kümenizi 10 parçaya bölerseniz, her bir parça tek tek doğrulama verisi olarak kullanılır ve geri kalan 9 parça ise eğitim verisi olarak kullanılır. Bu işlem 10 kez tekrar edilir ve her seferinde farklı bir parça doğrulama verisi olarak kullanılır.Performans değerlendirmesi için ise; her seferinde elde edilen doğruluk oranlarının ortalaması alınır.
Alt örnek.
K-Fold yöntemi; veri kümesi çok büyük değilse veya her veri noktasının önemi aynı ise kullanılabilir.
Ancak veri kümesi küçük ya da veri kümesinde önemli farklılıklar olmuş (Değişimler vb.) ise; bu doğrulama yöntemi ile elde edilen performans değerlendirmesi tutarlı olmayabilir.
Bu durumda diğer çapraz doğrulama yöntemlerine başvurmak daha uygun olabilir.
Yöntemi Iris veri seti üzerinde özet şekilde uyarlayacak olursak;
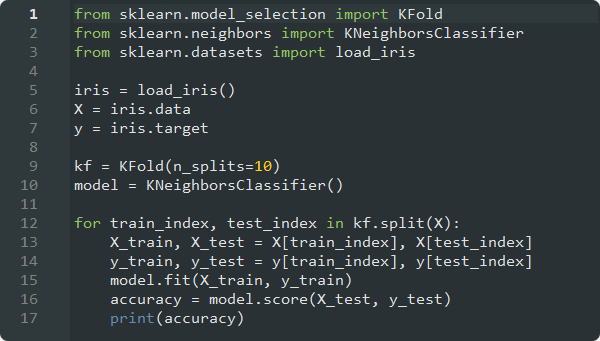
modeline ulaşıp,

skorlarını ve model performansını elde ederiz.
#ILGILI KUTUPHANELERIMIZI ANALIZIMIZE DAHIL ETTIK.
from sklearn.model_selection import KFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
#IRIS VERI SETINI ANALIZIMIZE DAHIL EDIP, ANALIZ PARAMETRELERIMIZE ATADIK.
iris = load_iris()
X = iris.data
y = iris.target
#VERI KUMEMIZI 10 ESIT PARCAYA AYIRIP, MODELIMIZI OLUSTURDUK.
kf = KFold(n_splits=10)
model = KNeighborsClassifier()
#OLUSAN HER ESIT VERI KUMESINI;
-EGITIM VERILERINI KULLANARAK EGITTIK,
-TEST VERILERINI KULLANARAK TEST ETTIK. (DOGRULAMA KONTROLU.)
SONUC OLARAK HER BIR PARCA ICIN SKOR DEGERINE ULASIP,MODEL PERFORMANASINI ELDE ETTIK.
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
print(accuracy) Holdout
Holdout Cross Validation (Ayırarak Çapraz Doğrulama) yöntemi; veri kümenizi eğitim ve test kümeleri olarak iki ayrı parçaya ayırarak veri kümeleri oluşturup işlemde bulunmaktadır.Veri setinin belirli bir yüzdesi test verileri olarak kullanılırken geri kalanı eğitim verileri olarak kullanılır.Bu yöntem; analiz öncesi veri setinin bölünmesiyle uygulanır ve veri seti sadece bir kez bölünür.
*Genellikle 0.20-0.25/0.80-0.75 arasında bölünmektedir. (1/3 Oranı)
Holdout yöntemi; veri setinin yeterli büyüklükte olduğu durumlarda kullanışlıdır.Çünkü test verileri yeterli sayıda veri noktası içermelidir, aksi durumda test verileri yeterli sayıda veri noktası içermeyebilir ve modelin doğruluğu yanıltıcı olabilir.
Yöntemi Iris veri seti üzerinde özet şekilde uyarlayacak olursak;
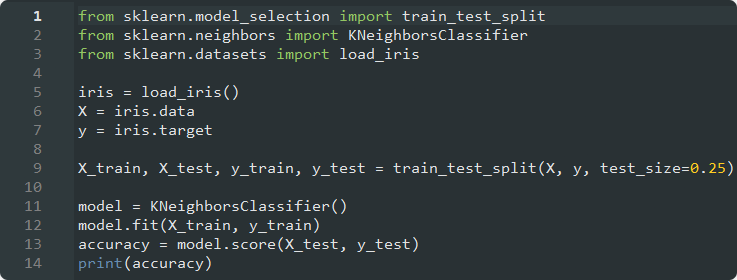
modeline ulaşıp,
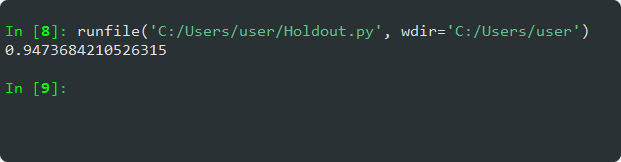
skorunu ve model performansını elde ederiz.
#ILGILI KUTUPHANELERIMIZI ANALIZIMIZE DAHIL ETTIK. from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.datasets import load_iris #IRIS VERI SETINI ANALIZIMIZE DAHIL EDIP, ANALIZ PARAMETRELERIMIZE ATADIK. iris = load_iris() X = iris.data y = iris.target #VERI KUMEMIZI TEST VE EGITIM OLARAK 2 PARCAYA AYIRIP (1-3 ORANLARINDA), MODELIMIZI OLUSTURDUK. X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25) #TEST VERILERI KULLANARAK SKOR DEGERINE ULAŞIP, MODEL PERFORMANASINI ELDE ETTIK. model = KNeighborsClassifier() model.fit(X_train, y_train) accuracy = model.score(X_test, y_test) print(accuracy)
Monte Carlo
Monte Carlo Cross Validation (MCCV – Monte Carlo Çapraz Doğrulama) yöntemi; veri setini rastgele olarak böler ve her seferinde farklı bölümleri kullanarak modeli eğitip, doğrulamasını yapararak işlemde bulunmaktadır.
Bu yöntem; veri setinde özellik seçimine dayalı performansın nasıl değişebileceğini incelemek içinde kullanılmaktadır.
*Scikit-Learn kütüphanesinde ShuffleSplit() fonksiyonu kullanılmaktadır.Bu fonksiyon; veri setini rastgele olarak böler ve her seferinde farklı bölümleri kullanarak modeli eğitir, doğrulamasını yapar.
Monte Carlo yöntemi; veri seti birden fazla kez bölündüğü için veri setinin büyüklüğü yeterliyse kullanılabilir.
*Bölünebilir bir veri kümesi mevcutsa.
Yöntemi Iris veri seti üzerinde özet şekilde uyarlayacak olursak;

modeline ulaşıp,

skorunu ve model performansını elde ederiz.
#ILGILI KUTUPHANELERIMIZI ANALIZIMIZE DAHIL ETTIK.
from sklearn.model_selection import ShuffleSplit
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
#IRIS VERI SETINI ANALIZIMIZE DAHIL EDIP, ANALIZ PARAMETRELERIMIZE ATADIK.
iris = load_iris()
X = iris.data
y = iris.target
#VERI SETINI 10 DEFA RASTGELE OLARAK BOLUP,
HER SEFERINDE %25'I TEST VERISI OLACAK SEKILDE MODEL EGITIM YAPIMIZI PLANLADIK.
ss = ShuffleSplit(n_splits=10, test_size=0.25)
model = KNeighborsClassifier()
#DOGRULUK ORANLARINI YAZMAK ICIN LISTE OLUSTURDUK.
accuracies = []
#HER BOLUME AIT MODELIMIZI EGITIP, DOGRULAMA YAPTIK.
HER DOGRULAMA ISLEMI SONUCUNDAKI DOGRULUK ORANINI/DEGERINI BULDUK.
for train_index, test_index in ss.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
accuracies.append(accuracy)
#DOGRULUK ORANI LISTEMIZI YAZDIRDIK.
print(accuracies)
Leave-P-Out
Leave-P-Out (P Veri Noktasını Bırakma (P Adet Dışında Bırakılan) Çapraz Doğrulama) yöntemi; veri setinden p veri noktasını doğrulama verisi, kalan veri noktalarını eğitim verisi olarak kullanarak işlemde bulunmaktadır.
Yani; yöntemde yer alan p parametresi doğrulama verisi olarak kullanılacak veri noktalarının sayısını belirmektedir.Eğer p=1’den farklı bir değere ayarlanırsa; her seferinde o değer kadar veri noktası doğrulama verisi olarak kullanılır.
*Bölünme/Ayırma değeri veriseti büyüklüğüne göre belirlenmeli.
Leave-P-Out yöntemi; veri setinin büyüklüğüne göre p değerinin arttırılmasında performansı etkileyebilir.
Özellikle veri seti küçükse doğrulama verisi olarak kullanılacak veri noktalarının sayısı arttıkça eğitim verisi olarak kullanılacak veri noktalarının sayısı azalacağı için modelin performansı düşebilir.
Yöntemi Iris veri seti üzerinde özet şekilde uyarlayacak olursak;

modeline ulaşıp,

skorunu ve model performansını elde ederiz.
#ILGILI KUTUPHANELERIMIZI ANALIZIMIZE DAHIL ETTIK.
from sklearn.model_selection import LeavePOut
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
#IRIS VERI SETINI ANALIZIMIZE DAHIL EDIP, ANALIZ PARAMETRELERIMIZE ATADIK.
iris = load_iris()
X = iris.data
y = iris.target
#VERI SETINI; VERI NOKTASI AYRIMI P=2 OLACAK SEKILDE PLANLADIK.
lp = LeavePOut(p=2)
model = KNeighborsClassifier()
#DOGRULUK ORANLARINI YAZMAK ICIN LISTE OLUSTURDUK.
accuracies = []
#HER AYRIMA AIT MODELIMIZI EGITIP, DOGRULAMA YAPTIK.
HER DOGRULAMA ISLEMI SONUCUNDAKI DOGRULUK ORANINI/DEGERINI BULDUK.
for train_index, test_index in lp.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
accuracies.append(accuracy)
#DOGRULUK ORANI LISTEMIZI YAZDIRDIK.
print(accuracies)
Repeated K-Fold
Repeated K-Fold (Tekrarlı K Katmanlı Çapraz Doğrulama) yöntemi; K-Fold Cross Validation yöntemini birden fazla kez uygulayarak işlemde bulunmaktadır.Bu yöntemde veri seti K eşit parçaya bölünür ve her parça tek tek doğrulama verisi olarak kullanılır.İlgili işlem K sayısı kadar tekrarlanır; her tekrar için model eğitilir ve doğruluk oranı hesaplanır.İşlemlerim sonunda ise bu doğruluk oranlarının ortalaması alınır ve modelin genel performans göstergesi oluşturulur.
Repeated K-Fold yöntemi; veri seti küçük veya veri noktalarının özellikleri arasında önemli bir zamanlama etkisi olduğunda kullanılabilir.Bu yöntem; genel olarak veri setinin her parçasının en az bir kez doğrulama verisi olarak kullanılmasını sağlar, bu sayede veri setinin her kısmının modelin performansını etkileyebileceği düşünülerek daha doğru bir doğrulama yapılmasını sağlar.
Yöntemi Iris veri seti üzerinde özet şekilde uyarlayacak olursak;
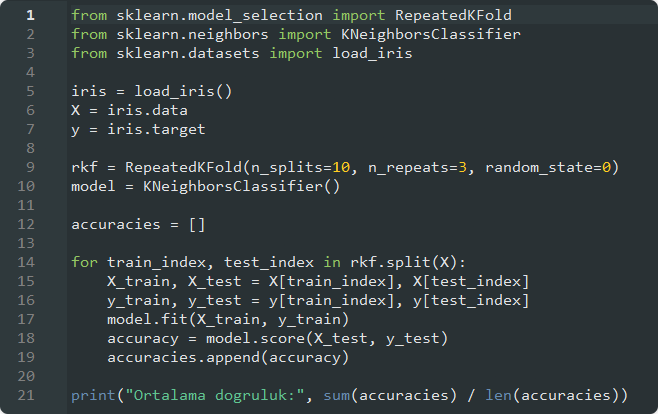
modeline ulaşıp,
skorunu ve model performansını elde ederiz.
#ILGILI KUTUPHANELERIMIZI ANALIZIMIZE DAHIL ETTIK.
from sklearn.model_selection import RepeatedKFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
#IRIS VERI SETINI ANALIZIMIZE DAHIL EDIP, ANALIZ PARAMETRELERIMIZE ATADIK.
iris = load_iris()
X = iris.data
y = iris.target
#VERI SETINI N_SPLIT=10 PARCAYA BOLEREK, N_REPEAT=3 KEZ DOGRULAMA VERISI
OLACAK SEKILDE KULLANILMASINI PLANLADIK.
rkf = RepeatedKFold(n_splits=10, n_repeats=3, random_state=0)
model = KNeighborsClassifier()
#DOGRULUK ORANLARINI YAZMAK ICIN LISTE OLUSTURDUK.
accuracies = []
#HER AYRIMA AIT MODELIMIZI EGITIP, DOGRULAMA YAPTIK.
HER DOGRULAMA ISLEMI SONUCUNDAKI DOGRULUK ORANINI/DEGERINI BULDUK.
for train_index, test_index in rkf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
accuracies.append(accuracy)
#DOGRULUK ORANI LISTEMIZI YAZDIRDIK.
print("Ortalama dogruluk:", sum(accuracies) / len(accuracies))
Bootstrap
Bootstrap (Önyüklemeli Çapraz Doğrulama) yöntemi; veri setinden rastgele ve tekrar edilebilen örneklemler alınarak doğrulama yapılmasını sağlamaktadır.Bu yöntemde veri setinden rastgele m sayıda veri noktası seçilir ve bu seçilen veri noktalarından yeni bir veri seti oluşturulur.Bu yeni veri seti kullanılarak model eğitilir ve doğruluk oranı hesaplanır.Bu işlem belirli bir sayıda tekrar edilir ve her tekrar için doğruluk oranlarının ortalaması alınır.
Sonunda bu ortalama doğruluk oranı modelin genel performansının bir göstergesi olarak kullanılır.
Bootstrap yöntemi; veri seti çok büyük değilse veya veri setinde önemli bir zamanlama etkisi yoksa kullanılabilir. Bu yöntem veri setinin büyük bir kısmının kullanılmasını sağlar ve bu sayede veri setinin her kısmının modelin performansını etkileyebileceği düşünülerek daha doğru bir doğrulama yapılmasını sağlar.
Yöntemi Iris veri seti üzerinde özet şekilde uyarlayacak olursak;

modeline ulaşıp,

skorunu ve model performansını elde ederiz.
#ILGILI KUTUPHANELERIMIZI ANALIZIMIZE DAHIL ETTIK. from sklearn.utils import resample from sklearn.neighbors import KNeighborsClassifier from sklearn.datasets import load_iris #IRIS VERI SETINI ANALIZIMIZE DAHIL EDIP, ANALIZ PARAMETRELERIMIZE ATADIK. iris = load_iris() X = iris.data y = iris.target #MODELIMIZI OLUSTURDUK. model = KNeighborsClassifier() #DOGRULUK ORANLARINI YAZMAK ICIN LISTE OLUSTURDUK. accuracies = [] #HER AYRIMA AIT RANGE(0,30)=30 DEFA TEKRARLI VERI SETI UZERINDE %75 ORANINDA
VERI NOKTASI SECIP; MODELIMIZI EGITTIK.
SONUCUNDA ISE SKORUMUZU HESAPLADIK. for i in range(0, 30): X_train, y_train = resample(X, y, n_samples=int(0.75*len(X)), random_state=i) X_test, y_test = resample(X, y, n_samples=int(0.25*len(X)), random_state=i) model.fit(X_train, y_train) accuracy = model.score(X_test, y_test) accuracies.append(accuracy) #DOGRULUK ORANI LISTEMIZI YAZDIRDIK. print("Ortalama dogruluk: ", sum(accuracies) / len(accuracies))
Dikkat:Alt kısımdaki gibi resample() kullanımında bulunmanız durumunda hata ile karşılaşcaksınız.
#X_train, X_test, y_train, y_test = resample(X, y, n_samples=int(0.75*len(X)), random_state=i) #FORMATINDA KULLANIMINDA; ValueError: not enough values to unpack (expected 4, got 3) #HATASI ALACAKSINIZ.
Rooling - Rolling Window
Rolling – Rolling Window (Kaydrımalı – Kayrdırmalı Bakış Çapraz Doğrulama) yöntemi; veri setinin belirli bir zaman aralığı içinde eğitim ve doğrulama verileri olarak bölünmesini uygulayarak işlemde bulunmaktadır.
Örneğin; 12 yıllık bir veri setinin son 5 yılını eğitim verileri olarak kullanırken, önceki yılları doğrulama verileri olarak kullanabilirsiniz.Daha sonra eğitim verileri kullanarak modeli eğitirsiniz ve doğrulama verilerini kullanarak modelin performansını ölçersiniz.Ardından eğitim verileri daha eski bir zaman aralığına kaydırılır ve süreç tekrarlanır.Bu şekilde veri seti zaman içinde değişirken modelin performansının nasıl değiştiğini izleyebilirsiniz.
Rolling validation yöntemi; ağırlıklı olarak zaman serisi veriler için kullanılmaktadır.
Yöntem; veri setinin tümünü eğitim ve test verileri olarak kullanmak yerine veri setinin bir kısmını eğitim verileri olarak kullanarak modelin performansını test eder.Aslında temel olarak veri setinin zaman içinde nasıl değiştiğini dikkate alarak modelin performansını test etmenizi sağlamaktadır.
*Zamana bağlı bir veri kümesi yapısı gerekmektedir.
Yöntemi Iris veri seti üzerinde özet şekilde uyarlayacak olursak;

modeline ulaşıp,

skorunu ve model performansını elde ederiz.
#ILGILI KUTUPHANELERIMIZI ANALIZIMIZE DAHIL ETTIK.
from sklearn.model_selection import TimeSeriesSplit
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
#IRIS VERI SETINI ANALIZIMIZE DAHIL EDIP, ANALIZ PARAMETRELERIMIZE ATADIK.
iris = load_iris()
X = iris.data
y = iris.target
#MODELIMIZI OLUSTURDUK.
VERI SETI N_SPLIT=5 PARCAYA BOLDUK.
tscv = TimeSeriesSplit(n_splits=5)
model = KNeighborsClassifier()
accuracies = []
#HER BOLUME AIT MODELIMIZI EGITIP, DOGRULAMA YAPTIK.
for train_index, test_index in tscv.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
accuracies.append(accuracy)
#DOGRULUK ORANI LISTEMIZI YAZDIRDIK.
print("Ortalama dogruluk: ", sum(accuracies) / len(accuracies))
İlgili yöntemleri genel olarak özetleyecek olursak;
##################################
#Randomized/Monte Carlo - MCCV Cross Validation - Rastgele Capraz Dogrulama
from sklearn.model_selection import ShuffleSplit
X = [...] # Veri kumesi verileri. / Ornegin; Iris=Setosa=0.42 ... vb.
y = [...] # Veri kumesi etiketleri. / Ornegin; Iris=Setosa,Versicolor... vb.
rs = ShuffleSplit(n_splits=5, test_size=0.2, random_state=0)
for train_index, test_index in rs.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model = ... # Model
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
print(accuracy)
##################################
#K-Fold Cross Validation - K Katli/Katmanli Capraz Dogrulama
from sklearn.model_selection import KFold
X = [...] # Veri kumesi verileri. / Ornegin; Iris=Setosa=0.42 ... vb.
y = [...] # Veri kumesi etiketleri. / Ornegin; Iris=Setosa,Versicolor... vb.
kf = KFold(n_splits=5)
for train_index, test_index in kf.split(X):
X_train, X_test = X[test_index]
y_train, y_test = y[train_index], y[test_index]
model = ... # Model
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
print(accuracy)
##################################
#Leave One/P Out Cross Validation - Biri (P) Disinda/Disarida Bırakilan Capraz Dogrulama
from sklearn.model_selection import LeaveOneOut
X = [...] # Veri kumesi verileri. / Ornegin; Iris=Setosa=0.42 ... vb.
y = [...] # Veri kumesi etiketleri. / Ornegin; Iris=Setosa,Versicolor... vb.
loo = LeaveOneOut()
for train_index, test_index in loo.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model = ... # Model
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
print(accuracy)
##################################
#Simple Cross Validation - Basit Capraz Dogrulama
from sklearn.model_selection import train_test_split
X = [...] # Veri kumesi verileri. / Ornegin; Iris=Setosa=0.42 ... vb.
y = [...] # Veri kumesi etiketleri. / Ornegin; Iris=Setosa,Versicolor... vb.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = ... # Model
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
print(accuracy)
##################################
#Repeated K-Fold Cross Validation - Tekrarli K Katmanli Capraz Dogrulama
from sklearn.model_selection import RepeatedKFold
X = [...] # Veri kumesi verileri. / Ornegin; Iris=Setosa=0.42 ... vb.
y = [...] # Veri kumesi etiketleri. / Ornegin; Iris=Setosa,Versicolor... vb.
rkf = RepeatedKFold(n_splits=5, n_repeats=10)
for train_index, test_index in rkf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model = ... # Model
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
print(accuracy)
##################################
#Holdout Cross Validation - Ayirarak Capraz Dogrulama
from sklearn.model_selection import train_test_split
X = [...] # Veri kumesi verileri. / Ornegin; Iris=Setosa=0.42 ... vb.
y = [...] # Veri kumesi etiketleri. / Ornegin; Iris=Setosa,Versicolor... vb.
X_train, X_test, y_train, y_test = train_test_split(X, y ,test_size=0.2 ,random_state=0)
model = ... # Model
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
print(accuracy)
##################################
#Rolling/Rolling Window Cross Validation - Kaydirmali/Kaydirmali Bakis ile Capraz Dogrulama
from sklearn.model_selection import TimeSeriesSplit
X = [...] # Veri kumesi verileri. / Ornegin; Iris=Setosa=0.42 ... vb.
y = [...] # Veri kumesi etiketleri. / Ornegin; Iris=Setosa,Versicolor... vb.
tscv = TimeSeriesSplit(n_splits=5)
for train_index, test_index in tscv.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model = ... # Model
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
print(accuracy)
##################################
#Bootstrap Cross Validation - Onyuklemeli Capraz Dogrulama
from sklearn.utils import resample
X = [...] # Veri kumesi verileri. / Ornegin; Iris=Setosa=0.42 ... vb.
y = [...] # Veri kumesi etiketleri. / Ornegin; Iris=Setosa,Versicolor... vb.
for i in range(10):
X_resample, y_resample = resample(X, y)
model = ... # Model
model.fit(X_resample, y_resample)
accuracy = model.score(X, y)
print(accuracy)
İlgili kod dökümüne;
https://github.com/miracozturk17/PythonCrossValidation
bağlantısı üzerinden erişebilirsiniz.
Buraya kadar genel olarak bilinen (Popüler/Meşhur) çapraz doğrulama tekniklerine değinmeye çalıştık.
Özetleyecek olursak; tüm bu yöntemler bir modelin performansının ölçülmesi için kullanılmaktadır.
Bu tekniklerin temel yöntemi veri setinin bölünmesi, modelin eğitimi ve test işlemlerinin gerçekleştirilmesidir.
Genel amaç ise kullanılan modelin gerçek dünya performansını daha doğru bir şekilde ölçebilmektir.
Hangi yöntem kullanılacağı ise veri seti ve amaç gibi faktörlere göre belirlenmektedir.
Gelecek yazılarda görüşmek üzere.
İyi çalışmalar…





