

Merhaba, iyi günler.
Bugün; insan dilini bilgisayarların anlayıp işleyebileceği bir forma dönüştürerek metin analizi, dil modelleme ve duygu analizi gibi alanlarda hem karmaşık dil yapılarını çözümleyen; hem de kullanıcı deneyimini iyileştiren Doğal Dil İşleme (NLP – Natural Language Processing) teknolojisinin mimari yapı ve yaklaşımları üzerine notlarımı paylaşacağım.
Şimdiden iyi okumalar.
***
Doğal Dil İşleme-NLP’nin tarihsel gelişimi boyunca, pek çok mimari yaklaşım geliştirilmiştir. Günümüzde en yaygın ve etkili yöntemler ise; RAG (Retrieval-Augmented Generation) ve Transformer tabanlı modeller olarak ifade edilmektedir.
Makalede Neler Var ?
Tarihsel Gelişim
Klasik Mimari Yaklaşımlar (1950-1980)
İlk NLP yöntemleri; mantıksal çıkarım ve sembolik kurallar temelinde çalışıyordu.
Bu dönemde geliştirilen sistemler; sabit sözlükler, dil bilgisi kuralları ve üretim kurallarıyla (Production Rules) donatılmıştı. Bir metin içerisindeki kelimeleri analiz etmek için ise; Parse Tree (Cümle Ağacı-Ayrıştırma Ağacı) gibi yapılar kullanılırdı.
Parse Tree; dilbilgisel yapıların ağaç biçiminde gösterimi olup, cümlenin dil bilgisi kurallarına (Gramer) göre nasıl oluştuğunu açıklar.
*Parse Tree; Berkeley Üniversitesi ders kaynağı…
Teknik mantıkta örnekleyecek olursak;
- S → NP VP: Bir cümle (S), bir isim öbeği (NP) ve ardından bir fiil öbeğinden (VP) oluşur.
- NP → N: En temel biçimiyle bir isim öbeği (NP), yalnızca bir ad (isim) içerebilir. Ancak çoğu durumda belirleyiciler (Det), sıfatlar (Adj) veya sayılar (NUM) ile genişletilebilir:
NP → (Det) (Adj) (NUM) N - N: Cümlede geçen temel isimleri temsil eder.
Örneğin; Atatürk, saygı, başarı… - TO → \”to\”: Mastar yapılarında kullanılan bağlayıcıdır.
Örneğin; başarmak için, gitmek. - PP → P NP: Bir edat öbeği (PP), bir edat (P) ve ardından gelen bir isim öbeğinden (NP) oluşur.
Örneğin; ulus için… - P: [Edatlar] Türkçedeki yer-yön ve ilgi belirten sözcükleri kapsar.
Örneğin; üzerine, hakkında, ile, gibi… - Det: [Belirleyiciler] Bir isimden önce gelen ve onun tanımlayıcısı olan sözcüklerdir.
Örneğin; bir, bu, o… - NUM: [Sayılar] Cümlelerde sayı belirten/tanımlanan öğelerdir.
Örneğin; sekizinci, üçüncü…
İfadeleri bir örnek ile açıklayacak olursak;
Örnek Cümle: Mustafa Kemal Atatürk için derin bir saygı besliyoruz.
NP → N
N → “Mustafa Kemal Atatürk”
VP → V PP
V → “besliyoruz” (yüklem/fiil)
PP → P NP
P → “için”
NP → Det Adj N
Det → “bir”
Adj → “derin”
N → “saygı”
Cümle Ağacı (Parse Tree) ise;
S
├── NP
│ └── N (“Mustafa Kemal Atatürk”)
└── VP
├── V (“besliyoruz”)
└── PP
├── P (“için”)
└── NP
├── Det (“bir”)
├── Adj (“derin”)
└── N (“saygı”)
şeklindedir.
Bu ve benzeri yaklaşımlar, her kelimenin anlamını sözlüklerden çekerek; kurallarla eşleştirip, cümlelerin yapısını belirlemeye çalışırdı.
ELIZA* (1966) bu dönemin en ikonik örneklerinden biridir. Joseph Weizenbaum tarafından geliştirilen ELIZA; kullanıcı girdisine uygun anahtar kelimeleri eşleştirerek, basit ama etkili cevaplar üretiyordu. Özellikle “DOCTOR” senaryosu, danışan-psikolog diyaloğunu taklit etmesiyle öne çıktı.
*ELIZA ismi; George Bernard Shaw’un ünlü oyunu “Pygmalion”daki karakter olan Eliza Doolittle’tan alınmıştır.
Oyunda Eliza; bir çiçekçi kızken, dil eğitimiyle “hanımefendi”ye dönüştürülür.
Kod mantığı örneği;
IF user_input CONTAINS "I am" THEN RESPOND "How long have you been $1?"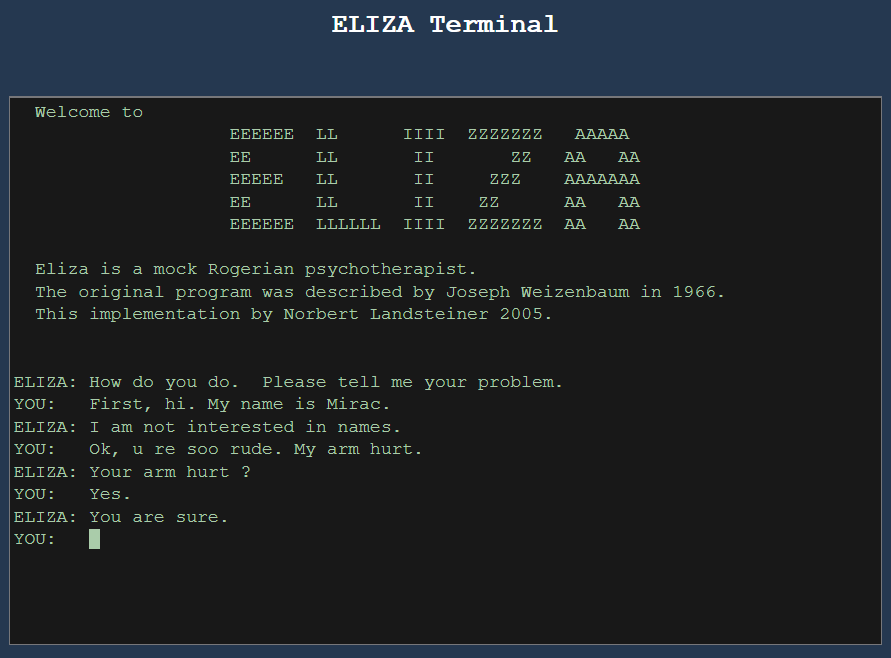
Bu yaklaşımda kullanıcı girdisiyle belirli anahtar kalıplar eşleştirilir ve önceden tanımlanmış bir çıktı döndürülür. Bu yöntem, anlamı bağlamdan bağımsız olarak ele aldığı için yalnızca yüzeysel analizler yapılabilir.
Deneyimlemeyi düşünürseniz;
bağlantıları ile çalışma disiplinini inceleyerek, terminal arayüzü üzerinden sohbet edebilirsiniz.
Farklı bir yaklaşım ile Case Grammar (Charles Fillmore, 1968) ise; fiillerin anlamının yalnızca bağlamda üstlendikleri Anlamsal Roller (Semantic Roles) ile birlikte çözülebileceğini savunur.
Bu roller arasında;
-Fail (Agent),
-Nesne (Patient),
-Araç (Instrument),
-Yer (Location),
-Hedef (goal),
-Kaynak (Source)
gibi kategoriler bulunur.
Bu yaklaşım; doğal dildeki anlamsal ilişkilerin biçimsel olarak temsil edilmesine imkan verir ve Semantic Role Labeling (SRL) gibi modern uygulamalara temel oluşturur.
Teknik mantıkta örnekleyecek olursak;
Örnek Cümle: Mustafa Kemal Atatürk için derin bir saygi besliyoruz.
Kodumuz;
import spacy_stanza # type: ignore
nlp = spacy_stanza.load_pipeline("tr")
doc = nlp("Mustafa Kemal Atatürk için derin bir saygi besliyoruz.")
for token in doc:
print(f"Kelime: {token.text}, Etiket (Dependency Type): {token.dep_}, Baş (Head Word): {token.head.text}")çıktımız ise;
Kelime: Mustafa, Etiket (Dependency Type): nsubj, Baş (Head Word): besliyoruz
Kelime: Kemal, Etiket (Dependency Type): flat, Baş (Head Word): Mustafa
Kelime: Atatürk, Etiket (Dependency Type): flat, Baş (Head Word): Mustafa
Kelime: için, Etiket (Dependency Type): case, Baş (Head Word): Mustafa
Kelime: derin, Etiket (Dependency Type): amod, Baş (Head Word): saygi
Kelime: bir, Etiket (Dependency Type): det, Baş (Head Word): saygi
Kelime: saygi, Etiket (Dependency Type): obj, Baş (Head Word): besliyoruz
Kelime: besliyoruz, Etiket (Dependency Type): root, Baş (Head Word): besliyoruz
Kelime: ., Etiket (Dependency Type): punct, Baş (Head Word): besliyoruzşeklindedir.
Bu çıktılar kullanılarak, semantik roller etiketlenebilir.
Örneğin, bu cümlede;
- Eylem: besliyoruz
- Fail (Gizli Özne): biz
- Hedef: Mustafa Kemal Atatürk
- Nesne: saygı
- Sıfat: derin
- Belirleyici: bir
ifadeleri için etiketleme gerçekleştirilebilir.
Bu yapıya yönelik, daha ileri düzey SRL için; AllenNLP veya BERT tabanlı modeller kullanılmaktadır.
Transition Network Grammar; geleneksel üretimsel dil bilgisi kurallarını, grafiksel ve algoritmik Geçiş Diyagramları (State Diagrams) biçiminde modelleyen bir yaklaşımdır.
Bu yapı; cümlelerin analizinde alternatif yol izlemeye olanak tanır.
Temel yapısı;
- Düğümler (Nodes): Dilsel kategorileri temsil eder.
Örneğin; NP, VP vb. - Geçişler (Arrows): Girdi sözcüğüne veya kurala göre ilerlemeyi tanımlar.
- Yinelemeli (Recursive) çağrılar: Alt kuralların işlenmesini sağlar.
Örneğin; NP içerisinde farklı bir NP.
Teknik mantıkta örnekleyecek olursak;
def parse_S(tokens):
if parse_NP(tokens):
return parse_VP(tokens)
return False
def parse_VP(tokens):
if tokens and tokens[0] in verbs:
tokens.pop(0)
if not tokens:
return True
return parse_NP(tokens) or parse_PP(tokens)
return False
def parse_NP(tokens):
if tokens and tokens[0] in nouns:
tokens.pop(0)
return True
return False
def parse_PP(tokens):
if tokens and tokens[0] in prepositions:
tokens.pop(0)
return parse_NP(tokens)
return False
nouns = ["Miraç", "kitap"]
verbs = ["okudu"]
prepositions = ["ile"]
tokens = ["Miraç", "kitap", "ile", "okudu"]
result = parse_S(tokens.copy())
print("Kalan:", tokens)
print("Sonuç:", result)
print("Geçerli cümle" if result else "Geçersiz cümle")Bu örnekte, her fonksiyon bir düğümü temsil eder ve geçişler; if-else yapılarıyla sağlanır.
Çalıştırıldığında ise;
Kalan: ['Miraç', 'okudu']
Sonuç: True
Geçerli cümleçıktısını vermektedir.
Bu yaklaşım ise, NLP’de; Parsing, Metin Analizi, Chatbot Sistemleri ve doğal dille yazılmış komutların yorumlanmasında kullanılmıştır.
İstatistiksel Yaklaşımlar (1980-2000)
1980’lerden itibaren; NLP alanında, istatistiksel yöntemler ön plana çıkmaya başladı.
Bu dönem; büyük metin koleksiyonlarından (Corpus) öğrenilen olasılıksal modellerin yükselişine tanıklık etti. Özellikle; etiketlenmiş verilerin artması ve bilgisayarların işlem gücündeki gelişmeler, bu modellerin başarısını ve kullanımını arttırdı.
Bunlara yönelik başlıcaları;
1.Brown Corpus* [Kaynak Dil: İngilizce]
- İlk genel amaçlı bilgisayarla işlenebilir metin koleksiyonudur (1961).
- Henry Kučera ve Winthrop Nelson Francis tarafından; Brown Üniversitesi’nde derlenen ve 500’den fazla ingilizce metin içeren, bir milyona yakın sözcükten oluşan bir derlem.
- Yaklaşık; 1 milyon kelime içermektedir.
- Computational Linguistics (Hesaplamalı Dilbilim) alanında yaygın olarak kullanılmaktadır.
- Genel fihrist için; Brown Corpus – Wikipedia
*Corpus: Kolleksiyon, Külliyat.
2.Penn Treebank [Kaynak Dil: İngilizce]
- Gramatikal Analizler (Parse Tree), Sözcük Türü Etiketleme (POS-Part of Speech) ve daha fazlasını içerir.
Sözcük türü etiketlemeleri;
-İsim (Noun – NOUN)
-Özel İsim (PROPN)
-Fiil (Verb – VERB)
-Sıfat (Adjective – ADJ)
-Zarf (Adverb – ADV)
-Edat (Adposition – ADP)
-Bağlaç (Conjunction – CCONJ)
-Zamir (Pronoun – PRON)
-Belirteç (Determiner – DET)
-Sayı (Numeral – NUM)
-Ünlem (Interjection – INTJ)
-Noktalam İşareti (PUNCT)
belirteçleri ile gerçekleştirilmektedir.
Örnek olarak ise;
Cümle: Miraç Natural Language Processing Journal dergisinde bir yayın yayınladı.
-PROPN: Miraç
-PROPN: Natural Language Processing Journal
-NOUN: dergisinde
-DET: bir
-NOUN: yayın
-VERB: yayınladı
-PUNCT: . (Nokta)
ifade edilebilir. - University of Pennsylvania tarafından oluşturulduğu için ‘Penn’ adını almıştır. İçeriğinde ise; Wall Street Journal gazetesinde yer almış olan makalelerden alınan metinleri yer almaktadır.
- Araştırmacılar ve geliştiriciler arasında, en çok kullanılan; etiketlenmiş dil kaynaklarından biridir.
- Genel fihtrist için; LDC Catalog – Penn Treebank
3.Türkçe Ulusal Derlemi (TUD) – Turkish National Corpus (TNC) [Türkçe]
- Türçe Ulusal Derlemi – TUD olarakta ifade edilmektedir.
- Türkiye Türkçesini temsil eden, dengeli ve temsili bir korpustur.
- 50 milyon kelime içerir.
- Açık erişim tam sürümü yoktur, ancak bilgi ve talep formu için:
- Kullanım kaynağı için; TNC Web Sitesi
Kullanım için, öncelikle üyellik işlemleri gerekmektedir;
https://v3.tnc.org.tr/register
bağlantısı üzerinden üyelik işlemlerini gerçekleştirebilirsiniz.
Kayıt işlemi sonrasında ise;
mail doğrulaması ve kullanıcı onaylama süreci başlamaktadır;
Doğrulama sonrasında, araştırma ekranları aktive olmaktadır.
Basit bir sorgulama ile araştırma sürecine başlandığında,
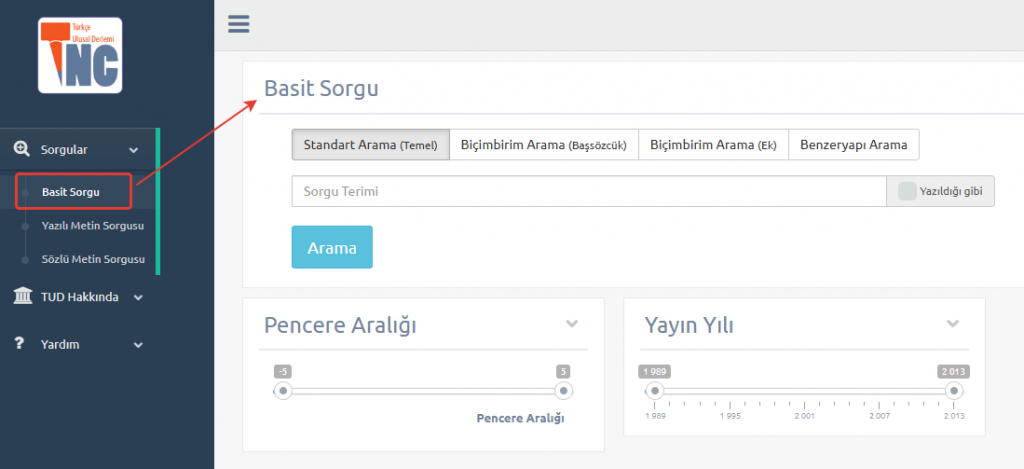
çeşitli kriter ve kıstaslarda araştırmada bulunabilmektesiniz;
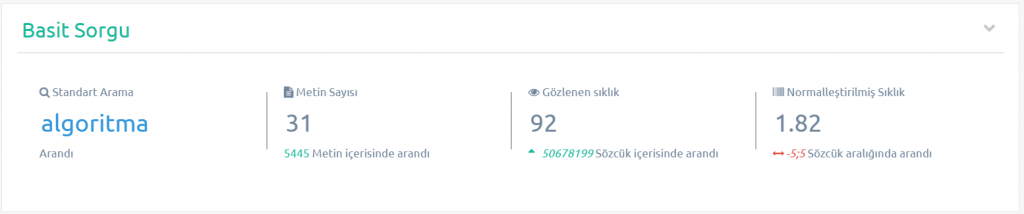
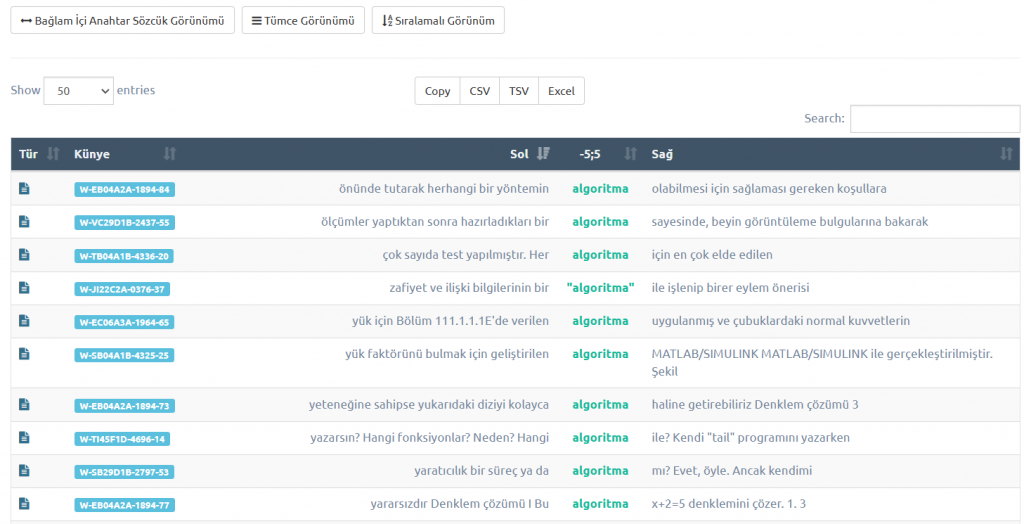
Buradaki araştırma sonuçlarını; bir öğrenme modelini geliştirme üzerine kullanabilmeniz için çeşitli veri çıktı türleride sağlanmaktadır.
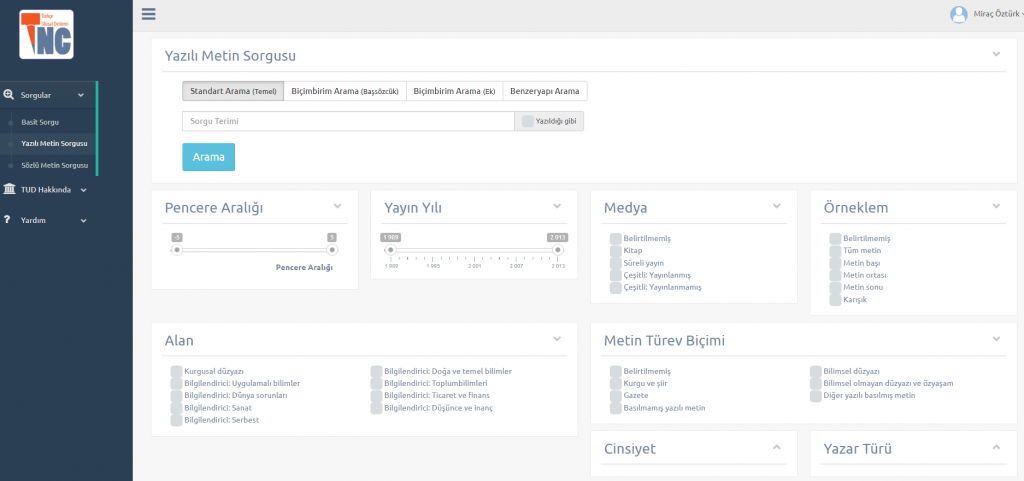
Yanı sıra, çeşitli tür ve içeriklerde Yazılı/Sözlü arama yapabileceğiniz özelliklerde içermektedir;

Yazılı Metin sorgulaması;
Sözlü Metin sorgulaması;
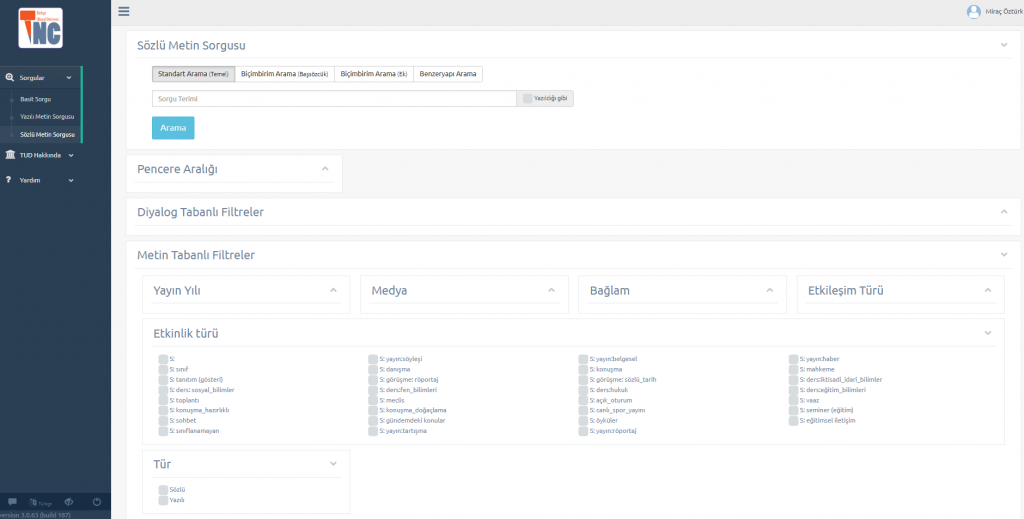
TUD hakkında biraz detaya inecek olursak; Türkçe Ulusal Derlemi (TUD) günümüz Türkçesinin dengeli, büyük ölçekli (50 milyon sözcük) ve genel amaçlı bir derlemi olarak tasarlanmıştır. Bu amaçla, daha önce başka dillerde yapılmış olan derlem oluşturma çabaları ve deneyimlerinden de yararlanılmıştır.
TUD’un oluşturulması sırasında, genel olarak Britanya Ulusal Derlemi’nin (British National Corpus) yapısı örnek alınmış ve Türkçe için gerekli durumlarda değişikliklere gidilmiştir.
TUD’un tüm oluşturma aşamalarında çeşitli açık-erişimli araçlar kullanılmış ve oluşturulan derlemin de araştırmacılara ve ticari olmayan kullanımlara açık ve erişilebilir olması hedeflenmiştir.
TUD Sürüm, 3.0; 50 milyon sözcükten oluşan, 24 yıllık bir dönemi (1990- 2013) kapsayan, günümüz Türkçesinin çok sayıda farklı alan ve türlerden yazılı ve sözlü örneklerini içeren, geniş kapsamlı, dengeli ve temsil yeterliliğine sahip, genel amaçlı bir referans derlemdir.
Kullanıcılar çok çeşitli kısıtlama ölçütleri ile (Medya, Metin Örneklemi, Konu Alanı, Türev Metin Biçimi, Yazar Cinsiyeti, Hedef Okur, Metin Türü vb.) sorgularını gerçekleştirebilirler.
Ayrıca TUD 3.0 sürümünde kullanıcılar, sözcük türüne ve eklere göre de sorgu yapabilmekte; çoksözcüklü birimleri arayabilmektedirler. Ayrıca sorgularını, düzenli ifadeler kullanarak da gerçekleştirebilmektedirler.
Emeği geçen tüm ilgililere, teşekkürü; bir borç biliriz…
4.METU-Sabancı Treebank [Türkçe]
- Türkçe için sözcük türü ve ayrıştırma (parsing) etiketleri içerir.
- Sıklıkla araştırmalarda kullanılır.
- Genel fihrist; GitHub – Universal Dependencies Turkish Treebank
Orta Doğu Teknik Üniversitesi-ODTÜ ve Sabancı Üniversitesi ortak çalışması olan ODTÜ Türkçe Derlemi – METU CORPUS bir bölümünü dil bilgisi yapılarına bölerek, Türkçenin kullanım değişkenliğini analiz etmede temel oluşturabilecek içeriğin, XML temelli yapılarda sunulduğu bir proje olarak yer almaktadır.
Genel proje bilgisi;
https://ii.metu.edu.tr/metu-corpora-research-group
Proje içeriğine ulaşmak için;
https://web.itu.edu.tr/gulsenc/treebanks.html
bağlantısını kullanabilirsiniz.
Bu bağlantıda,
alanından ilgili dosyayı cihazınıza indirebilirsiniz.
İndirme işlemini tamamladığınızda, ‘.conll’ uzatısında bir dosyaya ulaşacaksınız.
.conll uzantısı; CoNLL (Conference on Computational Natural Language Learning) formatında hazırlanmış dosyaları ifade etmektedir. Bu dosyalar; Doğal Dil İşleme (NLP) alanında özellikle Sözdizimsel (Syntax) ve Anlamsal (Semantic) etiketleme için kullanılmaktadır.
İndirmiş olduğunuz bu dosya içerisindeki bilgileri doğrudan inceleymemekteyiz.
*Uzantısını .txt olarak güncellerseniz görüntülemede bulunabilirsiniz.
Bunun için python üzerinde connlu ve tabulate kütüphaneleri ile hızlıca önizlemede bulunabiliriz;
import conllu # type: ignore
from tabulate import tabulate # type: ignore
def parse_conllu_to_table(path):
sentences = []
current_sentence = []
with open(path, encoding="utf-8") as file:
for line in file:
line = line.strip()
if not line:
if current_sentence:
sentences.append(current_sentence)
current_sentence = []
elif not line.startswith("#"):
columns = line.split("\t")
current_sentence.append(columns)
if current_sentence:
sentences.append(current_sentence)
return sentences
file_path = r'C:\\conllu\\METUSABANCI_treebank_v-1.conll'
parsed_sentences = parse_conllu_to_table(file_path)
for i, sentence in enumerate(parsed_sentences[:3], 1):
print(f"\n *** Cümle {i} ***")
print(tabulate(sentence, headers=[
"ID", "Form", "Lemma", "UPOS", "XPOS", "Feats", "Head", "DepRel", "Deps", "Misc"
], tablefmt="grid"))Çıktımız ise;
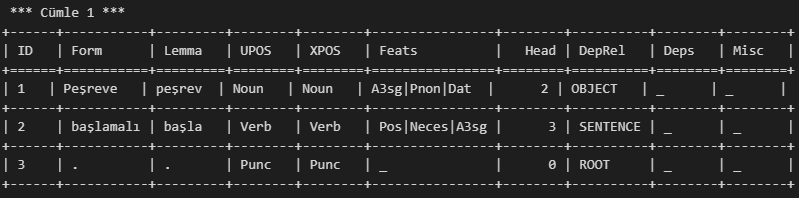
şeklindedir.
İlgili kaynağın içeriğini incelediğimizde ise;
| Sütun Adı | Açıklama | Toplam Veri Sayısı | Farklı (Tekil) Değer Sayısı | Örnek Değerler |
|---|---|---|---|---|
ID | Cümle içindeki kelimenin sıra numarası | ~48.000+ (kelime bazlı) | 1–~30 arasında değişen | 1, 2, 3… |
FORM | Kelimenin yüzey (görünen) biçimi | ~48.000 | ~11.000+ | “Ali”, “kalemle”, “yazdı” |
LEMMA | Kelimenin kökü (sözlük biçimi) | ~48.000 | ~7.500+ | “yaz”, “kalem”, “Ali” |
UPOSTAG | Evrensel sözcük türü etiketi | ~48.000 | ~15 | Noun, Verb, Adj, Pron, Punc, Conj, Det… |
XPOSTAG | Türkçeye özgü ayrıntılı sözcük türü | ~48.000 | ~20+ | Noun, Verb, Zero, Punc, DemonsP |
FEATS | Biçimbilimsel özellikler (morph. features) | ~48.000 | ~1.000+ kombinasyon | `A3sg |
HEAD | Bağlı olduğu baş kelimenin ID’si | ~48.000 | 0–30 arası | 0 (kök), 1, 2, 3… |
DEPREL | Bağlılık (dependency) türü | ~48.000 | ~30+ | ROOT, OBJECT, SUBJECT, MODIFIER, SENTENCE, POSSESSOR, DETERMINER |
DEPS | Ek bağımlılık bilgileri (genelde _) | ~48.000 | 1 | _ (boş) |
MISC | Diğer bilgiler (genelde _) | ~48.000 | 1 | _ (boş) |
Burdaki içerikte yer alan bigilerin detayına;
kaynağından ulaşabilirsiniz.
Emeği geçen tüm ilgililere, teşekkürü; bir borç biliriz…
5.Sözlü Türkçe Derlemi (STD) – Spoken Turkish Corpus (STC) [Türkçe]
- Doğal, günlük konuşmalardan oluşan sözlü dil içerikleri içerir.
- Yaklaşık 400.000 sözcük barındırı.
- Sözdizimsel ve morfolojik etiketleme
Transkripsiyon (uluslararası standartlara uygun)
etiketleme yapıları içerir. - Genel fihrist; std-bilgileri.pdf
Sözlü Türkçe Derlemi (STD) ya da İngilizce adıyla; Spoken Turkish Corpus (STC) Türkiye Türkçesinin sözlü kullanımına dair sistematik, etiketlenmiş ve akademik çalışmalarda kullanılmak üzere hazırlanmış bir dil veritabanıdır. Bu derlem; özellikle sözlü dilin yapısını ve kullanım özelliklerini incelemek isteyen araştırmacılar için önemli bir kaynaktır.
Erişim; https://std.metu.edu.tr bağlantısı üzerinden sağlanmaktadır.
Erişim gerçekleştirildiğinde ise;

ekranı ile karşılaşılmaktadır.
Bu ekran genel olarak Dereleme yönelik bilgiler ve kullanım sürecine yönelik yönergeler içermektedir.
Kullanım talep formu ve sonrasındaki yazılı iletişim ile gerçekleştirilmektedir.
Örnek formu ise;
şeklinde yer almaktadır.
STD temel özellikleri ise;
detayları ile sistemde yer almaktadır.
Emeği geçen tüm ilgililere, teşekkürü; bir borç biliriz…
6.OpenSubtitles Corpus [Kaynak Dil: Çok Dilli]
- Film altyazılarından alınmış, çok dilli paralel metinler sunar.
- Özellikle çeviri modelleri için uygundur.
- 1950’lerden günümüze kadar olan filmler/diziler ile; 22 milyardan fazla kelime, 400 milyondan fazla cümle çifti içerir.
- Yapısı; Cümle hizalamalı (bilingual) ve Zaman damgalı altyazılardan oluşmaktadır.
- 60+ dil desteği içermektedir. (İngilizce, Türkçe, Almanca, Japonca, vb.)
- Genel fihrist; GitHub – The Open Parallel Corpus
olarak örneklendirilebilir.
An itibari ile;
- 1.212 korpus/derlem,
- Toplam 58.851.021.412 cümle çifti,
- 747 dil
barındırmaktadır.
Bu değerler, tüm OPUS koleksiyonunun; %94,85’ini oluşturan 100 korpusu göstermektedir.
Bunun yanı sıra, bünyesinde barındırdığı dil çiftleri için çeşitli makine çevirisi (MT) modellerinin otomatik değerlendirme metrikleride yer almaktadır;
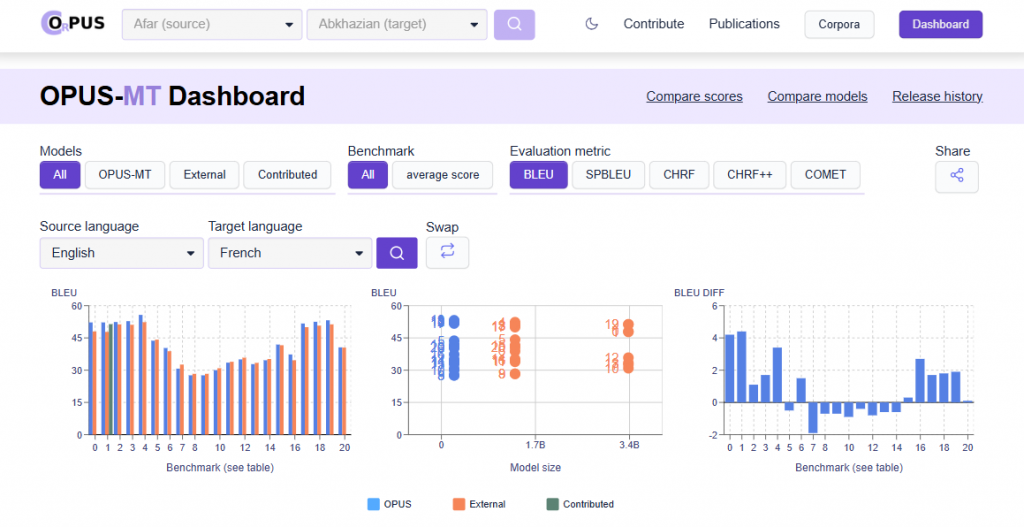
Bir sonraki devam yazımızda;
- Naive Bayes Sınıflandırıcıları
- Gizli Markov Modeli (HMM)
- N-Gram Modelleri
ana yaklaşımları üzerine incelemelerimize devam edeceğiz.
İyi çalışmalar…





