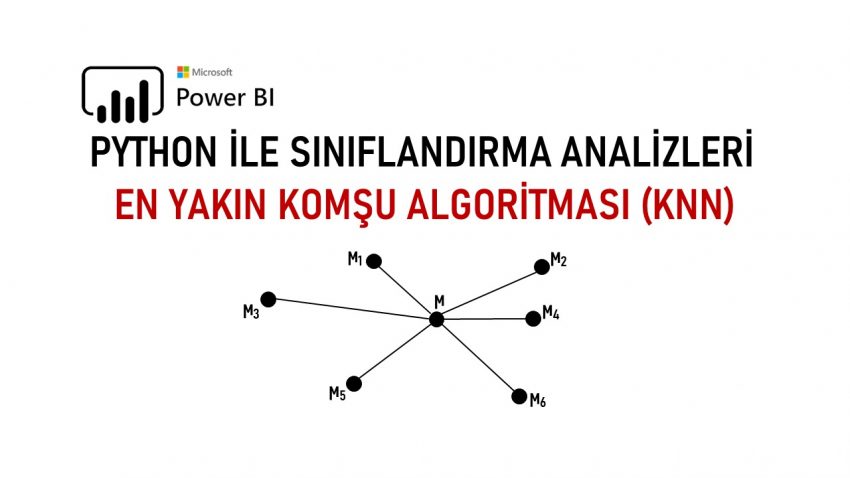
Bugün; çeşitli veri kümeleri üzerinde özel işlemler ile farklı çözümlemeler için yapılandırılmış denetimli/gözetimli öğrenme algoritmalarından, kümeleme yöntemleri ile benzerlik (k) değerleri ele alınarak geliştirilmiş En Yakın Komşu (K-Nearest Neighbours – KNN) algoritması üzerine çeşitli bilgi ve çözümlemeler aktarmaya çalışacağım.
KNN (K-Nearest Neighbours, K-En Yakın Komşu) Algoritması Nedir ?
En Yakın Komşu Algoritması – EYKA (K-Nearest Neighbours – KNN); sınıflandırma işleminde bulunulacak örnek veri noktasının bulunduğu sınıfın (öğrenim kümesi) ve en yakın komşunun (elemanın), k değerine (benzerliğe) göre belirlendiği bir denetimli/gözetimli makine öğrenme yöntemi olarak ifade edilmektedir.
Literatür üzerinde yer alan temel/basit ifadesi ile tekrar tanımlanacak olursa;
Sınıfı bilinmeyen verilerin, eğitim setindeki diğer veriler ile karşılaştırılıp bir uzaklık ölçümü gerçekleştirilmesi sonucu hesaplanan uzaklığa göre henüz bir sınıfa atanamamış verinin, en ideal (optimal) sınıfa atanarak sınıflandırılması olarak ifade edilmektedir.
KNN algoritması; hem sınıflandırma hem de regresyon çalışmaları içerisinde kullanılması yönü ile popüler olarak tercih edilen bir algoritmadır.
Genel sınıflandırma algoritmaları (modelleri) kendi çözümleri içerisinde bir sınıflayıcı oluşturarak sistem içerisindeki her veri değeri üzerinde bu sınıflayıcıyı kullanır.Genel olarak bu sınıflandırma algoritmalarına nazaran KNN algoritması her değer için, ilgili değere en yakın komşu kümesi üzerinden bir sınıflayıcı oluşturarak değerleri sınıflandırır. (Doğruluk değeri ideal seviyedeki bir sınıflandırma çözümü.)
Elbetteki tekrarlanan bu sınıflayıcı algoritmik çözüm, sınıflandırma sürecinin zaman almasına neden olmaktadır. Bundan ötürü literatürde Tembel Öğrenci Algoritması (Yöntemi) olarak da ifade edilmektedir.
Algoritmaya yönelik uzaklık hesaplaması tipleri (sadece bir kısmı);
ManhattanUzaklık Hesaplaması; Rn içinde (uyarlanabilir) eksenler boyunca dik açılarda ölçülen iki nokta arasındaki mesafe hesaplaması olarak ifade edilmektedir.
ChebyshevUzaklık Hesaplaması; Rn içinde (uyarlanabilir) herhangi bir koordinat boyutu boyunca iki vektör arasındaki en büyük fark içeren mesafe hesaplaması olarak ifade edilmektedir.
HammignUzaklık Hesaplaması; Rn içinde (uyarlanabilir) iki vektör arasındaki farklı olan değerlerin sayısı olarak ifade edilmektedir. (Değer sayısı mesafe olarak ifadelendirilir.)
Minkowski Uzaklık Hesaplaması gerçekleştirilirken denkleme yönelik üç ana gereksinim mevcuttur. Bunlar;
Sıfır Vektör (Zero Vector): Başlangıç ve bitiş noktası aynı olan yönlü doğru parçalarının temsil ettiği vektör olarak ifade edilmektedir. Boyu/Uzunluğu sıfır olan vektördür. Temsili olarak;
Skaler Faktör (Scaler Factor): Tanımlı bir vektörün yönünü koruyan ama uzunluğunu değiştirmeyen değer olarak ifade edilmektedir.
Üçgen Eşitsizliği Çözümlemesi (Triangle Inequality Analysis) : Geometrik eleman olan üçgene ait kenarların uzunluklarına yönelik eşitsizlik çözümü olarak ifade edilmektedir.
MahalanobisUzaklık Hesaplaması; Rn içinde (uyarlanabilir) verinin varyans-kovaryans yapısını göz önüne alan ve tekil bir aykırı gözlem denemesi için kullanılabilen bir uzaklık formülü tanımlayan mesafe hesaplaması olarak ifade edilmektedir.
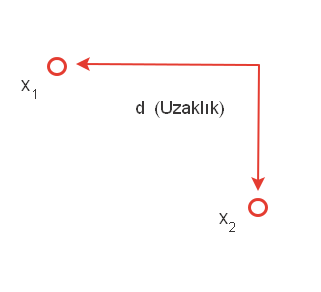
HaversineUzaklık Hesaplaması; Rn içinde (uyarlanabilir) enlem ve boylam ve değerleri kullanarak bir küre üzerindeki (Genel olarak) mesafe hesaplaması olarak ifade edilmektedir.
LevenshteinUzaklık Hesaplaması; iki dizi/dizilim arasındaki benzerliği derecelendirmek olarak ifade edilmektedir. (Değer sayısı mesafe olarak ifadelendirilir.)
Sørensen-DiceUzaklık Hesaplaması; sezgisel ağırlıklı olarak iki veri seti arasındaki örtüşme yüzdesi incelenip 0 ile 1 arasında bir değer verilerek değerlendirme gerçekleştirilmesi olarak ifade edilmektedir. (Değer mesafe olarak ifadelendirilir.)
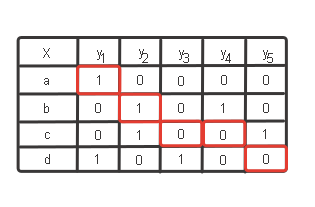
JacckardUzaklık Hesaplaması; veri setleri üzerindeki benzerlik ya da farklılıkları inceleyip 0 ile 1 arasında bir değer verilerek değerlendirme gerçekleştirilmesi olarak ifade edilmektedir. (Değer mesafe olarak ifadelendirilir.)
KNN (K-Nearest Neighbours, K-En Yakın Komşu) Algoritması Uygulama Örneği
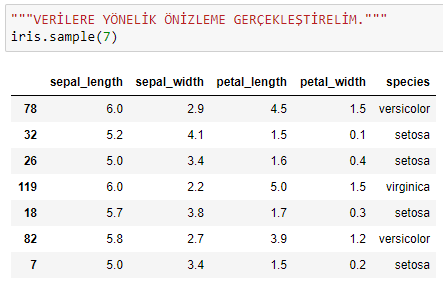
KNN (K-Nearest Neighbours, K-En Yakın Komşu) algoritması uygulamasına örnek olarak, çokça duyulan ve kullanılan Iris Veri Seti üzerinden basit bir örnek ile çözümlemelerde bulunalım.
Iris Veri Seti 3 Iris bitki türüne (Iris Setosa, Iris Virginica ve Iris Versicolor) ait, her bir türden 50 örnek olmak üzere toplam 150 örnek sayısına sahip bir veri setidir.
Iris Veri Seti içerisinde;
Sınıflar (Türler);
Iris Setosa,
Iris Versicolor,
Iris Virginica.
Veri Özellikleri (Ortak Özellikler);
Sepal Uzunluk (cm),
Sepal Genişlik (cm),
Petal Genişliği (cm)
Petal Uzunluk (cm).
özellik ve değerleri bulunmaktadır.
Dilerseniz hızlıca analizimizi gerçekleştirmek için adımlarımızı uygulamaya başlayalım.
19-Grid Search nesnemiz üzerinden doğruluk değeri ve k parametre değerlerini görüntüleyelim;
>>>print(“{} doğrulundaki en iyi k = {}”.format(grid.best_score_,grid.best_params_))
20-Grid Search nesnemiz üzerinden çapraz doğrulama, standart sapma, en iyi sıra ve k parametre değerlerini görüntüleyelim;
>>>print(“En iyi k değeri için sıra= {}, k = {}, en yüksek doğruluktaki çapraz doğrulama = {} ve en düşük standart sapma ={}”. format(grid_table.at[grid.best_index_,’rank_test_score’],grid_table.at[grid.best_index_,’params’], grid_table.at[grid.best_index_,’mean_test_score’],grid_table.at[grid.best_index_,’std_test_score’]))
21-Analizimiz üzerindeki en iyi sınıflandırıcı parametre değeri ise;
>>>print(“En iyi sınıflandırıcı parametre değeri: {}”.format(grid.best_estimator_))
21-(15) adım üzerinde yer alan listemiz elemanlarımız (komşular) göz önüne alındığında doğruluk değerleri grafik üzerinde görselleştirilirse;
>>>graphic = grid.cv_results_[‘mean_test_score’] graphic plt.figure(figsize=(10,5)) plt.plot(k_list,graphic,color=’navy’,linestyle=’dashed’,marker=’o’) plt.xlabel(‘K Komşu Numarası’, fontdict={‘fontsize’: 15}) plt.ylabel(‘Doğruluk’, fontdict={‘fontsize’: 15}) plt.title(‘K Değeri Komşu Bazlı Doğruluk Grafiği’, fontdict={‘fontsize’: 30}) plt.xticks(range(0,31,3),) plt.show()
En Yakın Komşu algoritmasına yönelik basit veri seti üzerinden bir analiz gerçekleştirdik. Mevcut algoritma kompleks ve bağlantısı yüksek olan veriler üzerinde çokça tercih edilmektedir. Elbette ki avantaj ve dezavantajlar yer almaktadır.
Görselleştirme işlemleri için dilerseniz Python üzerinde ki çeşitli kütüphaneleri kullanarak dilerseniz de geçmiş dönemlerde uygulamış olduğumuz Power BI ile görselleştirme (1–2) çalışmalarından faydalanabilirsiniz.









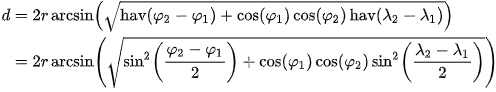


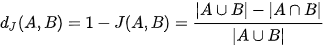
























 Business Intelligence Specialist
Business Intelligence Specialist