Bugün; çeşitli veri kümeleri üzerinde özel işlemler ile farklı çözümlemeler için yapılandırılmış gözetimli öğrenme algoritmalarından uzayı tabanlı makine öğrenme yöntemi olan Destek Vektör Makinası – DVM üzerine çeşitli bilgi ve çözümlemeler aktarmaya çalışacağım.
(Karar) Destek Vektör Makinesi – DVM (Support Vector Machine – SVM) ; modellediğimiz veri kümemiz üzerinde belirlediğimiz eğitim verilerindeki herhangi bir noktadan en uzak olan iki sınıf arasında bir karar sınırı bulan vektör uzayı tabanlı makine öğrenme yöntemi olarak ifade edilmektedir.
İlk olarak AT&T Labs‘taVladimir Vapnik ve arkadaşları tarafından geliştirilen Destek Vektör Makineleri (DVM) ileri yönde beslemeli yeni bir ağ kategorisi olarak da yorumlanmaktadır.
Destek Vektör Makinası algoritmasının, sınıflandırma problemlerinin çözümlenmesinin doğrultusunda ortaya çıktığı ifade edilmektedir. İlerleyen zaman dilimlerinde ise regresyon problemleri için de uyarlamaları gerçekleşmiştir.
Zaman geçtikçe çok faklı yaklaşımlar ile uyarlamaları genişletilmiş ve geliştirilmiştir.
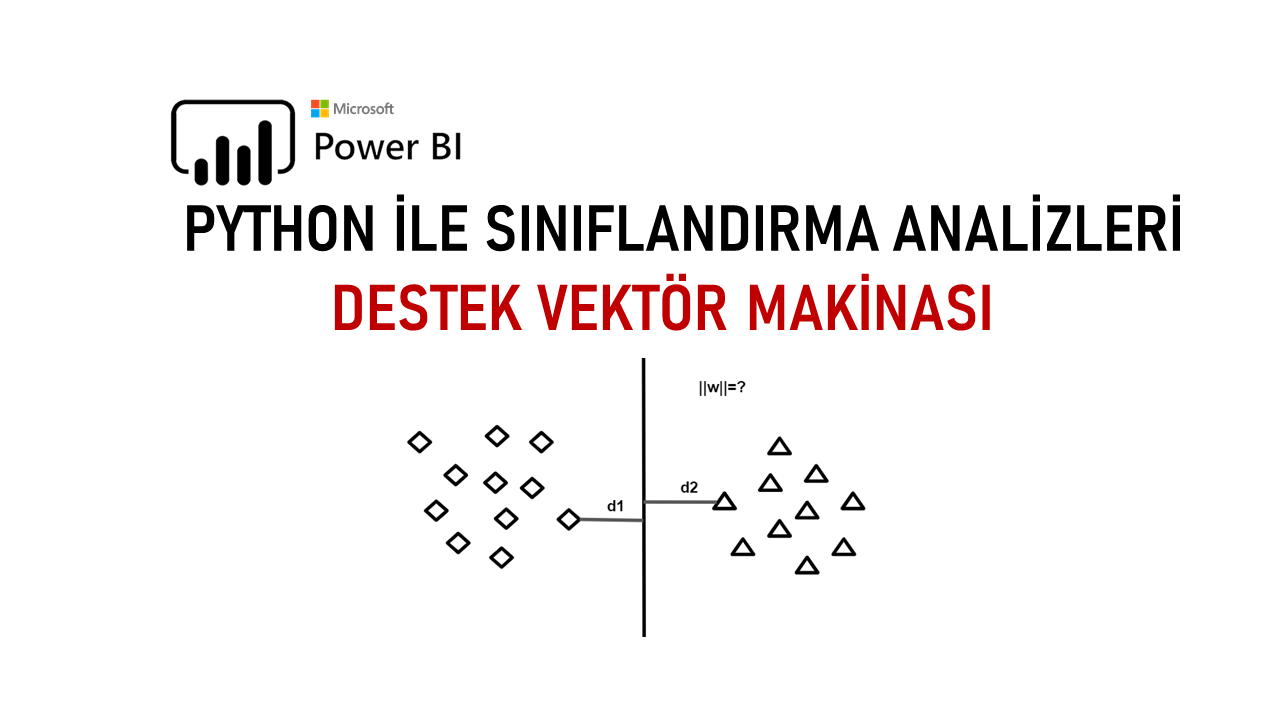
Genel manada Veriler (Küme Elemanları – Veri Grupları)
Ayrılma Noktası (Point of Departure) : Tek boyutta iki veri grubunu birbirinden ayıran en yakın iki noktanın orta noktası olarak ifadelendirilmektedir.
İki boyutta (temsili olarak);
Destek Vektörleri (Support Vector) : Bir sınıftan (gruplara ait elemanlardan) hiper düzeleme en yakın olan farklı veri grubu noktaları olarak ifadelendirilmektedir. *(Üst görsel temsili olarak oluşturulmuştur.)
Hiper Düzlem (Hyper Plane) : Bir sınıfa ait iki veri grubunu (en az) birbirinden ayıran düzlem olarak ifadelendirilmektedir.
Marjin (Margin) : En yakın gruba ait veri noktası ve hiper düzlem arasındaki mesafeleri en üst düzeye çıkarmak için doğru hiper düzlemi belirlememize yardımcı olan mesafe olarak ifadelendirilmektedir.
Çeşitli çalışma durumlarında değerlerimiz-örneklerimiz marjinine göre farklı bölgelerde bulunabilir.
Hard Margin : Değerlerimizin-Örneklerimizin marjin bölgesi dışında bulunması olarak ifade edilmektedir. Soft Margin : Değerlerimizin-Örneklerimizin marjin bölgesinde bulunması olarak ifade edilmektedir.
Üç boyut ise (temsili olarak);
şeklinde görselleştirilebilir. *İki boyutta bulunan aynı çözüm öğeleri üçüncü boyutta da tanımlanmaktadır.
Genel olarak Destek Vektör Makinaları (DVM);
Doğrusal Destek Vektör Makinaları ve
Doğrusal Olmayan Destek Vektör Makinaları
şeklinde ikiye ayrılmaktadır.
Doğrusal Destek Vektör Makinaları
Doğrusal Destek Vektör Makinası uygulamasında:
Veri grupları doğrular (çizgiler) ile kolay bir şekilde ayrılıp, veriler düzlem-hiper düzlem ile sınıflandırılmaktadır.
Temsili olarak;
Doğrusal Olmayan Destek Vektör Makinaları
Doğrusal Olmayan Destek Vektör Makinası uygulamasında:
Veri grupları doğrular (çizgiler) ile ayrılamayabilir (eğri olabilir), veriler düzlem-hiper düzlem ile sınıflandırılamaz ise Çekirdek (Kernel) Fonksiyonu-Yöntemi kullanılır.
Temsili olarak;
Çekirdekleme (Kernel Trick(s))
Düşük boyutlardaki çözümlenemeyen-anlamlandırılamayan verilerin boyutlandırılıp ek işlemler ile işlenerek anlamlandırılması Çekirdekleme (Kernel Trick – Kernel Method) olarak ifade edilmektedir.
Polinomal Çekirdekleme ve Gaussian Çekirdekleme olarak ikiye ayrılmaktadır.
Polinomal Çekirdekleme (Polynomial Kernel)
Polinomal Çekirdekleme; çalıştığımız uzayda bir üst-alt uzaya geçiş ile boyutlandırma işlemi gerçekleştirdiğimiz-uyguladığımız çözümleme modelidir.
Veri modelleri üzerindeki boyutlandırma işlemlerinde ağırlıklı olarak 2.Boyuttan → 3.Boyuta ya da genel olarak ifade edecek olursak N.Boyut’a geçiş gerçekleşmektedir. (N∈ Z+ ∧ N ≥ 3 )
Gauss Çekirdekleme (Gaussian RBF Kernel); Destek Vektör Makinaları belirlenip, her bir noktanın belirli noktalara ne ölçüde benzediğini normal dağılım yöntemi ile hesaplayıp sınıflandırma işlemini gerçekleştirdiğimiz çözümleme modelidir.
Bu modelde dağılım genişliği hiper parametre değeri (Gama – Gamma : γ) ile kontrol edilmektedir.
Çözümleme modele uygulanırken; model Overfit* olmasına karşın gama değeri düşürülür, Underfit* olmasına karşın ise gama değeri arttırılır.
*Overfit : Modelin veri setini öğrenmek yerine ezberlemesi olarak ifade edilir. *Underfit: Modelin veri setini ezberlemek yerine anlamlandırmaya çalışıp anlamlandıramaması olarak ifade edilir. *Overfitting : Model ve veri seti üzerindeki aşırı uygunluk olarak ifade edilir.
Destek Vektör Makinası Örneği
Destek Vektör Makinası uygulamasına örnek olarak, çokça duyulan ve kullanılan Iris Veri Seti üzerinden basit bir örnek ile çözümlemelerde bulunalım.
Iris Veri Seti 3 Iris bitki türüne (Iris Setosa, Iris Virginica ve Iris Versicolor) ait, her bir türden 50 örnek olmak üzere toplam 150 örnek sayısına sahip bir veri setidir.
Iris Veri Seti içerisinde;
Sınıflar (Türler);
Iris Setosa,
Iris Versicolor,
Iris Virginica.
Veri Özellikleri (Ortak Özellikler);
Sepal Uzunluk (cm),
Sepal Genişlik (cm),
Petal Genişliği (cm)
Petal Uzunluk (cm).
özellik ve değerleri bulunmaktadır.
Dilerseniz hızlıca analizimizi gerçekleştirmek için adımlarımızı uygulamaya başlayalım.
1-Gerçekleştireceğimiz analizler için kullanacağımız kütüphaneleri sırası ile projemize dahil edelim; (Sklearn, Numpy, MatplotLib)
>>> from sklearn import datasets >>>from sklearn import svm >>>from sklearn.metrics import accuracy_score >>>import numpy as np >>>import matplotlib.pyplot as plt
2-Modeli oluşturmak için üzerinde çalışacağımız Iris Veri Seti’ni proje içerisine aktaralım;
>>> iris = datasets.load_iris()
3-Sepal Uzunluk ve Sepal Genişlik üzerinden türler arasındaki korelasyonları gözlemlemek için keşif verisi adımlarımızı sırası ile gerçekleştirelim;
keşif verilerini işleyerek grafik üzerinde görselleştirelim;
4-Sepal Uzunluk ve Sepal Genişlik üzerinde gerçekleştirdiğimiz türler arasındaki korelasyonları gözlemlemek için keşif verisi adımlarını şimdi Petal Uzunluk ve Petal Genişlik için gerçekleştirelim;
keşif verilerini işleyerek grafik üzerinde görselleştirelim;
5-Çiçeğin ait olduğu sınıfın türünü tahmin etmek için ilk iki özelliği (Sepal Uzunluk/Genişlik) kullanarak bir DVM / SVM modeli oluşturalım. (Petal Uzunluk/Genişlik alternatif olarak kullanılabilir.)
>>> X = iris.data[:, :2] >>> y = iris.target
#ALTERNATIF KULLANIM. # X = iris.data[:, 2:] # y = iris.target
6-Çeşitli çekirdekler kullanarak DVM / SVMkarar sınırlarını çizmek için bir model ağacı oluşturalım;
7-Oluşturduğumuz yapımız için Lineer ve Lineer Olmayan (Polinomal ve Gauss) modellemeler üzerinden çekirdek işlemleri gerçekleştirelim;
>>> kernels = [“linear”, “rbf”, “poly”] for kernel in kernels: svc = svm.SVC(kernel=kernel).fit(X, y) plotSVM(“kernel=” + str(kernel))
çekirdek işleme işlemlerimizi gerçekleştirdikten sonra sınıflandırma modelimizi görselleştirirsek;
çıktılarına ulaşırız.
8-Farklı Gama (Gamma : γ) değerleri (0.1, 1, 10, 100) üzerinden çeşitli çekirdekleri gözlemleyerek hiperparametre ayarı oluşturalım;
>>> gammas = [0.1, 1, 10, 100] for gamma in gammas: svc = svm.SVC(kernel=’rbf’, gamma=gamma).fit(X, y) plotSVM(‘gamma=’ + str(gamma))
Genel olarak gama değeri arttıkça model uyumunda artış gözlemlenmektedir.
9-C* (Hata Değeri / Ceza Değeri) parametresi üzerinde belirli değerler (0.1, 1, 10, 100, 1000) belirleyerek gözlemde bulunalım.
C*=Sorunsuz bir karar sınırı ile eğitim noktalarının doğru şekilde sınıflandırılması arasındaki dengeyi kontrol eder.
>>> cs = [0.1, 1, 10, 100, 1000] for c in cs: svc = svm.SVC(kernel=’rbf’, C=c).fit(X, y) plotSVM(‘C=’ + str(c))
Küçük veri kümelerinde C* (Hata Değeri / Ceza Değeri) parametresi göz ardı edilebilir. Fakat yüksek ölçekteki veri kümelerinde bu büyük hatalara neden olabilir.
10-Son olarak ise uyguladığımız modelin doğruluğunu çekirdek modelinde lineer yapıyı (Doğruluk Yüzdesi) baz alarak hesaplayalım;
Oluşturduğumuz DVM / SVM modelimiz bize %82 oranında doğruluk değeri sağlamaktadır.
Burada daha hassas Gama ve C değerleri saptanarak doğruluk değeri optimuma yükseltilebilir. Böylelikle oluşturacağımız sınıflandırma işlemi için daha net/doğru sonuçlar elde edebiliriz.
İlgili verilerin işlenmesinin yanı sıra görselleştirilmesi de analiz işlemleri adına önem arz etmektedir.
Görselleştirme işlemleri için dilerseniz Python üzerinde ki çeşitli kütüphaneleri kullanarak dilerseniz de geçmiş dönemlerde uygulamış olduğumuz Power BI ile görselleştirme (1–2) çalışmalarından faydalanabilirsiniz.
Günlük Hayatta Destek Vektör Makinası Uygulamaları
































 Business Intelligence Specialist
Business Intelligence Specialist