Bugün; çeşitli veri kümeleri üzerinde özel işlemler ile farklı çözümlemeler için yapılandırılmış denetimli/gözetimli öğrenme algoritmalarından regresyon ve diğer analizler için eğitim aşamasında çok sayıda karar ağacı oluşturarak problemin tipine göre sınıf/sonuç tahmini gerçekleştiren toplu öğrenme yöntemi olan Rastgele Orman (Random Forest) algoritması üzerine çeşitli bilgi ve çözümlemeler aktarmaya çalışacağım.
Random Forest (Rastgele Orman) algoritması; birden çok karar ağacı üzerinden her bir karar ağacını farklı bir gözlem örneği üzerinde eğiterek çeşitli modeller üretip, sınıflandırma oluşturmanızı sağlamaktadır.
Kullanım kolaylığı ve esnekliği; hem sınıflandırma hem de regresyon problemlerini ele aldığı için benimsenmesini ve kullanımının yaygınlaşmasını hızlandırdı.
Algoritmaya yönelik en beğenilen nokta ise; veri kümeniz üzerinde çeşitli modellerin oluşturulması ile kümenizi yeniden ve daha derin keşfetme imkanı sunmasıdır.
Algoritma;
Analiz edilecek veri seti hazırlanır, (Analiz edilecek küme oluşturulur, gerekli görülürse veri temizlemesi gerçekleştirilir.)
Algoritma her bir örnek için karar ağacı oluşturur ve her bir karar ağacının tahmini değer sonucu oluşur,
Tahmin sonucu oluşan her değer için oylama gerçekleştirilir, *(Sınıflandırma problemi için Modu (Mode), Regresyon problemi için Ortalamayı (Mean))
Son olarak algoritma son tahmin için en çok oylanan değeri seçerek sonuç oluşturur.
adımları ile analiz gerçekleştirmektedir.
Rastgele Orman (Random Forest) Uygulama Örneği
RF (Random Forest, Rastgele Orman) algoritması uygulamasına örnek olarak, çokça duyulan ve kullanılan Iris Veri Seti üzerinden basit bir örnek ile çözümlemelerde bulunalım.
Iris Veri Seti 3 Iris bitki türüne (Iris Setosa, Iris Virginica ve Iris Versicolor) ait, her bir türden 50 örnek olmak üzere toplam 150 örnek sayısına sahip bir veri setidir.
Iris Veri Seti içerisinde;
Sınıflar (Türler);
Iris Setosa,
Iris Versicolor,
Iris Virginica.
Veri Özellikleri (Ortak Özellikler);
Sepal Uzunluk (cm),
Sepal Genişlik (cm),
Petal Genişliği (cm)
Petal Uzunluk (cm).
özellik ve değerleri bulunmaktadır.
Dilerseniz hızlıca analizimizi gerçekleştirmek için adımlarımızı uygulamaya başlayalım.
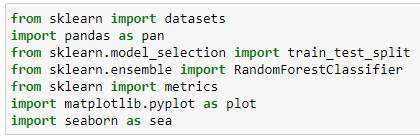
>>> from sklearn import datasets import pandas as pan from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn import metrics import matplotlib.pyplot as plot import seaborn as sea
datasets: Kullanacağımız veri kümesini çalışmaya dahil etmek için, (Iris)
pan: İçeri aktardığımız veri kümesinin bir çok boyutlu olarak kullanacağımız veri çerçevesini (DataFrame) oluşturmak için,
train_test_split: Eğitim ve Test kümesi işlemleri kullanımı için,
RandomForestClassifier: Rastgele Orman modelini kullanmak için,
metrics: Tahminlememizde doğruluk hesaplaması kullanmak için,
plot: Görselleştirme kullanmak için,
sea: Görselleştirme kullanmak için
ilgili kütüphaneleri projemize aktarmaktayız.
2-Çalışmamıza ilgili verilerimizi dahil edelim ve önizleme gerçekleştirelim;
7-Veri kümemizi test ve eğitim/öğrenme kümeleri olarak ikiye bölelim-ayıralım; (Test-Train) *Verileri; 35% Test, 65% Eğitim olarak ayıralım. *test_sizeile verilerin %kaçının test için kullanılacağını ifade belirleyebilmektesiniz. (Örneğimizde %35.) *train_sizeile verilerin %kaçının eğitim için kullanılacağını ifade belirleyebilmektesiniz. *shuffleile verilerin bölünmeden karıştırma uygulanıp-uygulanmayacağınız belirleyebilmektesiniz. *random_stateile bölünmeden önce verilere-veriye uygulanan karıştırmayı kontrol edebilmektesiniz.
8-Veri kümemizi bölme-ayırma işleminden sonra modeli eğitim seti üzerinde eğitip, test seti üzerinde tahminler gerçekleştirelim; *Verileri; 120 ağaç sayısı olarak ele alalım. *n_estimators ile maksimum oylama veya tahmin ortalamalarını almadan önce inşa etmek istediğiniz ağaç sayısını belirleyebilmektesiniz. *min_sample_leaf ile daha önce bir karar ağacı oluşturduysanız, minimum örnek yaprak boyutunun önemini anlayabilir ve sonrasında değer üzerinden sayısını belirleyebilmektesiniz. *min_sample_split ile dahili düğümü bölmek için gereken minimum örnek sayısını belirleyebilmektesiniz. *max_depth ile ağacın maksimum derinliğini belirleyebilmektesiniz. Kullanılmaz ise varsayılan olarak 0, tüm yapraklar saf olana veya tüm yapraklar min_samples_split örneklerinden daha azını içerene kadar düğümler genişletilmektedir.
12-Rastgele Orman sınıflandırıcımızı bir seviye daha derinleştirip, eğitimde bulunalım; *bootstrap ile ağaç oluştururken önyükleme örneklerinin kullanılıp kullanılmadığı kontrol edebilmektesiniz. Alt örnek boyutu; eğer bootstrap=True (varsayılan) ise max_samples parametresi ile kontrol edilmekte, aksi takdirde her bir ağacı oluşturmak için tüm veri seti kullanılmaktadır. *class_weight ile formdaki sınıflarla ilişkili ağırlıkları belirleyebilmektesiniz. *criterion ile bir bölünmenin kalitesini ölçme işlevini belirleyebilmektesiniz. Desteklenen kriterler Gini Safsızlığı/Kirliliği için “gini”, bilgi kazancı için “entropi” değerleri kullanılmaktadır. *max_features ile bir düğümü ayırırken dikkate alınacak maksimum özellik sayısını belirleyebilmektesiniz. *max_leaf_nodes ile maksimum kullanılacak yaprak sayısını belirleyebilmektesiniz. *min_impurity_decrease ile safsızlık/kirlilik değerlerini belirleyebilmektesiniz. *min_impurity_split ile safsızlık/kirlilik bölünmesi değerini belirleyebilmektesiniz. *min_weight_fraction_leaf ile bir yaprak düğümde olması gereken ağırlıklar toplamının minimum ağırlıklı değerini belirleyebilmektesiniz. *n_jobs ile paralel olarak çalıştırılacak iş sayısını belirleyebilmektesiniz. *oob_score ile tahmin hatalarını hesaplayabilmektesiniz. *verbose ile ayrıntı düzeyini belirleyebilmektesiniz. *warm_start ile işlem sonucu dahilinde önceki uygun çözümü yeniden kullanmak yerine, yeni bir orman oluşturulmasını sağlayabilmektesiniz. (EK Parametreler ve bilgilendirmeleri.)
13-Özelliklere yönelik önem puanlarını değerlendirelim; *sort_values ile verilerinizi belirlemiş olduğunuz sütuna/parametreye göre sıralayabilmektesiniz. sort_values(by=’sıralanacak sütun’, ascending=False)
Önem değeri düşük olan özellikleri/parametreleri (Sepal Width) analizimizden çıkardıktan sonra doğruluk değerinin arttığını görebilirsiniz.*Yanıltıcı verilerin/parametrelerin analizden çıkarılması.
Görselleştirme işlemleri için dilerseniz Python üzerinde ki çeşitli kütüphaneleri kullanarak dilerseniz de geçmiş dönemlerde uygulamış olduğumuz Power BI ile görselleştirme (1–2) çalışmalarından faydalanabilirsiniz.
Günlük Hayatta Algoritma Uygulama Alanları
Finans-Bankacılık Sektörü
Kredi ve Risk Değerlendirilmesi (Analizleri),
Dolandırıcılık Değerlendirmeleri (Fraud)
Opsiyon Fiyatlama Sorunu Analizleri
Sağlık Hizmetleri Sektörü
Kısmi Biyolojik Hesaplamalar
Gen Analizleri
Biyobelirteç Keşfi ve Analizleri
E-Ticaret Sektörü
Çapraz Satış Analizleri
Müşteri Öneri Sistemleri
Avantaj Dezavantaj
Rastgele Orman algoritması avantajları olarak;
Sınıflandırma ve Regresyon problemleri üzerinde kullanılabilmektedir, (Çok yönlü esnek çözüm imkanı)
İyi tahminleme oluşturmanızı sağlayan güçlü hiperparametreler bulunmaktadır,
Yüksek öneme sahip özelliklerin belirlenmesinde kolaylık sağlamaktadır,
Aşırı Uyum/Öğrenme (Over Fit) problemini önlemektedir-azaltmaktadır,
Eksik verileri (Bilinmeyen) işlemek için önemli bir çözümdür,
Büyük veri kümeleri için verimli işleme ve sonuç üretmektedir,
Kural tabanlı bir yaklaşım kullandığı için verilerin normalleştirilmesi gerekli olmamaktadır,
Paralelleştirilebilir-Paralel işlemler gerçekleştirilebilmektedir. (Analiz ve işlem sürecinizi çalıştırmak için birden fazla makineye bölebilirsiniz. n_jobs)
Rastgele Orman algoritması dezavantajları olarak;
Yapısal olarak oluşturmuş olduğu fazlaca çözüm (Ağaç) sayısından dolayı biraz yavaş sonuç üretmektedir, (Eğitim hızlı, tahmin uzun) (Özellikle gerçek zamanlı tahminlemeler için)
Daha doğru bir tahminleme için daha yavaş sonuçlanan bir modelle yüksek sayıda çözüm (Ağaç) gerekmektedir,
Verilerin ekstrapolasyonunda* ideal değildir, *Ekstrapolasyon; bilinen veri noktalarının ayrık kümesi dışında yeni veri noktaları oluşturma işlemidir.
Veriler çok seyrek olduğunda iyi sonuçlar üretmemektedir, (Özelliklerin alt kümesi ve önyüklenen örnek değişmez bir uzay üretmektedir.)
Tanımlayıcı bir araç değil, tahmine dayalı bir modelleme aracıdır. (Yani; verilerinizdeki ilişkilerin bir tanımını arıyorsanız, diğer yaklaşımlara yönelmeniz daha iyi olacaktır.)
Bu bölümde genel manada Sınıflandırma metoduna ait Rastgele Orman (Random Forest) algoritmasına değinmeye çalıştım.

















 Business Intelligence Specialist
Business Intelligence Specialist